
서론
프로그래머스에서 SQL 쿼리 문제를 풀다가 이제까지 별 생각없이 사용해 왔던 NOT IN 연산자에서 예상치 못한 결과 값이 나오는 경우가 있었다. 서치해보니 비교 대상에 NULL이 포함된 경우에 생기는 문제였는데, 이와 관련해서 찾아보니 공부가 필요한 내용이 꽤 있어서 정리하게 되었다.
(마지막 결론단에 요약본으로 정리도 해두었으니 본론에서는 흐름 정도만 파악하면 충분하다!)
먼저 본론에 들어가기 전에 해당 토픽을 생각해볼 수 있는 리트코드의 문제를 공유한다.
[ 문제 ]
Each node in the tree can be one of three types:
"Leaf": if the node is a leaf node.
"Root": if the node is the root of the tree.
"Inner": If the node is neither a leaf node nor a root node.
Write an SQL query to report the type of each node in the tree.
Return the result table in any order.

[ 정답 쿼리 ]
※ type 필드
- Root :
p_id가 NULL인 경우 - Leaf :
p_id가 NULL이 아니면서, 다른 노드의p_id가 아닌 경우 - Inner :
p_id가 NULL이 아니면서, 다른 노드의p_id인 경우
SELECT id
, CASE WHEN p_id IS NULL THEN 'Root'
WHEN id NOT IN (SELECT p_id FROM Tree WHERE p_id IS NOT NULL) THEN 'Leaf'
ELSE 'Inner' END AS type
FROM Tree
ORDER BY 1;
[ 처음 틀렸던 쿼리 ] (비교)
SELECT id
, CASE WHEN p_id IS NULL THEN 'Root'
WHEN id NOT IN (SELECT p_id FROM Tree) THEN 'Leaf'
ELSE 'Inner' END AS type
FROM Tree
ORDER BY 1;
본론
위의 리트코드 문제의 정답 쿼리와 틀린 쿼리의 차이점은 NOT IN 연산자의 비교 대상에 오는 서브쿼리 안에서의 WHERE p_id IS NOT NULL 의 유무이다.
즉, NOT IN 연산자의 비교 대상에 NULL이 존재하면 의도치 않은 잘못된 결과가 출력된다는 것인데, 그 이유에 대해 알기 위해서는 크게 4가지 개념을 알아야 한다.
1. NULL은 무엇인가?
NULL에 대한 정확한 이해를 하기 위해서는 메모리 공간에 대한 이해가 필요하지만, 그냥 쉽게 한마디로 정의하자면 NULL은 NULL이다.
NULL은 0도 아니고, *‘ ‘(SP)*도 아니고, FALSE도 아니다. NULL은 그저 NULL일 뿐이며, 다른 표현으로는 알 수 없는 값, 정의할 수 없는 상태, 아무 것도 없는 값이라고 볼 수 있다.
그렇다면 이런 NULL 값과 연산이나 비교를 하게 되면 그 결과는 어떻게 될까?


첫 번째 표에서 상수와의 연산(+-*/)이나 비교(=, ≠)의 결과는 모두 NULL이 나왔다.
두 번째 표에서 TRUE, FALSE와 같은 boolean 과의 비교 결과 역시 NULL이 나왔다.

결론부터 말하자면 NULL에 대한 연산은 따로 정해진 연산자 IS를 사용해야 원하는 결과값을 얻을 수 있다.
위의 표를 보면, NULL IS NULL의 결과는 1(TRUE), NULL IS NOT NULL의 결과는 0(FALSE)가 나왔지만
NULL에 비교 연산자(=, ≠)를 사용하면 그 결과는 무조건 NULL이 출력됨을 확인할 수 있다.
여기서 한 가지 알아야 할 개념이 UNKNOWN이다
지금까지 NULL 은 FALSE와는 다르다고 계속해서 말해왔는데, 그럼 SQL은 이 NULL 값을 어떻게 처리할까?
결론부터 얘기하자면
- SQL의 처리 방식은 TRUE/FALSE/UNKNOWN 이렇게 세 가지로 나눌 수 있다.
- 그리고 연산의 결과 NULL이 나오는 경우를 SQL은 UNKNOWN으로 처리한다.
대부분 T/F에 대해서는 잘 알고 있지만 UNKNOWN에 대해서 익숙하지 않을 수 있다(나 역시도 그랬다). 그리고 이 UNKNOWN 이라는 처리 방식이 FALSE와 다름을 아는 것이 오늘의 토픽을 이해하는 출발점이 된다.
위에서 봤던 이 예시들을 다시보면, 3 = NULL의 결과는 FALSE가 아니라 NULL이고, SQL은 이를 UNKNOWN으로 처리한다는 것!
2. IN, NOT IN 의 작동방식
그럼 다시 서론으로 돌아가서, NOT IN의 비교대상에 NULL이 포함되면 대체 무슨 문제가 생기길래 의도한 결과를 내지 못하는 것일까?
이는 IN, NOT IN의 작동 방식과 WHERE절의 성질에 해답이 있다.
1) IN, NOT IN의 작동 방식
먼저 IN은 한마디로 “fancy version of =” 라고 보면 된다.
아래의 두 쿼리문은 동치 관계이다. 즉, IN은 OR로 연결될 다수의 비교 조건문을 묶어줄 뿐, 그 역할은 =와 같다는 것이다.
SELECT '출력됩니다'
WHERE 1 IN (1,3,5);
SELECT '동치니까 당연히 출력됩니다'
WHERE (1 = 1) OR (1 = 3) OR (1 = 5);반대로 NOT IN 연산자는 ≠(같지 않다) 와 같다.
2) WHERE절의 성질
SQL 기초단계에서 배우겠지만 WHERE절은 그 결과가 TRUE인 값만 조회 조건에 포함시킨다.

그럼 이 두 가지 성질을 유념하면서 NOT IN과 NULL이 함께 쓰인 예제를 보자. 위의 TEST_1이라는 테이블로부터 num NOT IN (1,3,NULL) 조건을 만족하는 row들을 출력하고 싶다.
예상한 결과로는 num=2,4인 행이 출력되지 않을까 싶지만 결과는 그렇지 않다.
SELECT *
FROM TEST_1
WHERE num NOT IN (1,3,NULL);
그 이유는 num NOT IN (1,3,NULL) 라는 조건을 풀어써보면 알 수 있다.
(num != 1) OR (num != 3) OR (num != NULL)- 먼저 num = 1, 3은
(num != 1) OR (num != 3)에서 FALSE 판정을 받고 조회조건에서 제외 - num = 2, 4는
(num != 1) OR (num != 3)에서는 걸리지 않지만(num != NULL)에서 UNKNOWN(NULL) 판정을 받고 조회 조건에서 제외(1에서 NULL과의 비교 결과는 NULL이라고 했기 때문에) - 어떤 이유에서는 WHERE 절은 그 결과가 TRUE인 값만 조회 조건에 포함시키기 때문에 FALSE, UNKNOWN은 제외될 것이다
- 결론적으로 NOT IN의 비교대상에 NULL이 포함되면 모두 조회조건에서 모두 제외되어 아무것도 출력되지 않는다
- 먼저 num = 1, 3은
위의 설명을 명시적으로 확인해보고 싶다면 아래의 쿼리문을 확인해보면 된다.
SELECT
num
, num NOT IN (1,3,NULL) AS NOT_IN
FROM TEST_1;
NOT IN 연산의 결과 num =1,3은 FALSE(0), num =2,4는 FALSE(0) UNKNOWN(NULL)이 출력됨을 확인할 수 있다. FALSE, UNKNOWN 모두 WHERE 절에서 제외되므로 결론적으로는 아무 것도 출력되지 않았던 것.
※ 만약 TEST_1 테이블에서 num=2,4인 행이 출력되게 하려면 다음과 같은 쿼리로 바꿔주면 된다.
# 방법 1
SELECT *
FROM TEST_1
WHERE num NOT IN (1,3); # NULL을 비교 리스트에서 제외 = 서브쿼리에서 IS NOT NULL의 역할
# 방법 2
SELECT *
FROM TEST_1
WHERE num NOT IN (1,3,NULL) IS NOT FALSE; # IS NOT FALSE = TRUE OR UNKNOWN
3. EXISTS, NOT EXISTS 의 작동방식
NOT IN 연산자를 검색하면 가장 많이 나오는 내용이 바로 EXISTS와의 비교이다.
※ 이 글의 시작은 NOT IN 연산자였지만, EXISTS와 함께 개념을 익히는 것이 전반적인 내용 이해에 도움이 되는 것 같아 EXISTS의 작동방식에 대해서도 알아보고자 한다.
EXISTS는 IN과 매우 비슷하다.
단 EXISTS는 외부쿼리를 통해 레코드를 가져와 내부쿼리에 값이 “존재하는지” 확인한다. (외부쿼리 → 내부쿼리)
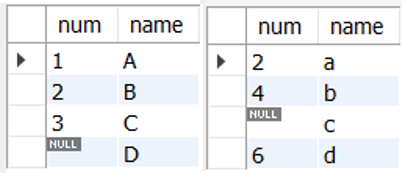
개인적으로 EXISTS는 IN 보다 사용한 경험이 거의 없기 때문에 바로 예시로 설명하도록 하겠다.
위의 TEST_2 테이블의 각 num 값에 대해 TEST_1에서 동일한 num 값을 가진 행이 없는지 확인하려고 한다.
SELECT *
FROM TEST_2
WHERE NOT EXISTS
(SELECT * FROM TEST_1 WHERE TEST_1.num = TEST_2.num);
- NOT EXISTS의 작동 방식
- TEST_2 테이블의 (num = 2, name = a) ROW
- 먼저 외부쿼리의 TEST_2 테이블에서 (num = 2, name = a)인 ROW를 들고, 내부(서브)쿼리로 접근
- 서브쿼리 실행 : WHERE문(
WHERE TEST_1.num = TEST_2.num)을 만족하는 결과(num = 2)와 일치 - 결론적으로 (num = 2, name = B)인 ROW는 서브쿼리에 존재하므로(EXISTS) WHERE 절은 FALSE
- 조회 조건에서 제외
- TEST_2 테이블의 (num = 4,6 , name = b,d) ROW
- 먼저 외부쿼리의 TEST_2 테이블에서 (num = 4,6 , name = b,d) ROW를 들고, 내부(서브)쿼리로 접근
- 서브쿼리 실행 : WHERE문(
WHERE TEST_1.num = TEST_2.num)을 만족하는 결과(num = 4, 6)가 없음 - 결론적으로 (num = 4,6 , name = b,d)인 ROW는 서브쿼리에 존재하지 않으므로(NOT EXISTS) WHERE 절은 TRUE
- 조회 조건에 포함
- TEST_2 테이블의 (num = NULL , name = c) ROW
- 먼저 외부쿼리의 TEST_2 테이블에서 (num = NULL , name = c) ROW를 들고, 내부(서브)쿼리로 접근
- 서브쿼리 실행 : WHERE문(
WHERE TEST_1.num = TEST_2.num)을 만족하는 결과가 없음- 참고로 TEST_1 테이블에도 num = NULL이 있지만 NULL = NULL 의 결과는 UNKNOWN이라 WHERE 조회조건에서 제외됨
- 결론적으로 (num = NULL , name = c)인 ROW는 서브쿼리에 존재하지 않으므로(NOT EXISTS) WHERE 절은 TRUE
- 조회 조건에 포함
- TEST_2 테이블의 (num = 2, name = a) ROW
위의 예제처럼 EXISTS / NO EXISTS 연산자는 결과의 존재 여부만을 평가하며, 설사 그 대상이 NULL이더라도 그 NULL이 존재/비존재 한다면 WHERE절의 TRUE 조건을 충족시킬 수 있다!
4. NOT IN, NOT EXISTS 의 차이
1. 지금까지 내용을 잘 따라왔다면 NOT IN과 NOT EXISTS의 첫 번째 차이는 NULL 처리방식이라는 것을 알 수 있을 것이다.
SELECT num
, num NOT IN (SELECT num FROM TEST_1) AS Not_in
, NOT EXISTS (SELECT * FROM TEST_1 WHERE TEST_1.num = TEST_2.num) AS Not_exists
FROM TEST_2;
위 쿼리의 실행 결과를 보면, NULL로 인해 비교가 불가능한 경우 NOT IN 연산자에서는 모두 UNKNOWN(NULL) 처리가 되지만, NOT EXISTS의 경우 NULL 또한 존재/비존재 여부만 따져 TRUE/FALSE의 결과를 내는 것을 확인할 수 있다.
2. 다음으로 IN과 EXISTS 연산자는 동작 방식에서도 약간의 차이가 있다
- IN 연산자 : 내부쿼리에 먼저 접근하여 내부쿼리의 데이터를 외부쿼리에 공급 (내 > 외)
- EXISTS 연산자 : 외부쿼리에 먼저 접근하여 내부쿼리로 데이터를 공급 (외 > 내)
3. 성능
- IN 연산자 : EXISTS보다 직관적. 적은 용량의 데이터에 유리
- EXISTS 연산자 : 지연 평가 원리를 이용하므로 IN에 비해 속도나 성능면에서 좋음(대용량 데이터에 유리)
결론
NOT IN, NOT EXISTS의 상세한 동작 원리까지 알고 난 후 다시 돌아가 서론에서 보았던 리트코드의 문제 해답으로 아래 3가지 풀이 방식까지 모두 이해가 된다면, 해당 토픽에 대해서는 어느정도 숙지가 되었다고 생각한다.
-- 풀이 1) NOT IN + WHERE IS NOT NULL 조합
SELECT id
, CASE WHEN p_id IS NULL THEN 'Root'
WHEN id NOT IN (SELECT p_id FROM Tree WHERE p_id IS NOT NULL) THEN 'Leaf'
ELSE 'Inner' END AS type
FROM Tree
ORDER BY 1;
-- 풀이 2) NOT IN + IS NOT FALSE 조합
SELECT id
, CASE WHEN p_id IS NULL THEN 'Root'
WHEN id NOT IN (SELECT p_id FROM Tree) IS NOT FALSE THEN 'Leaf'
ELSE 'Inner' END AS type
FROM Tree A
ORDER BY 1;
-- 풀이 3) NOT EXISTS 사용
SELECT id
, CASE WHEN p_id IS NULL THEN 'Root'
WHEN NOT EXISTS (SELECT * FROM Tree B WHERE A.id = B.p_id) THEN 'Leaf'
ELSE 'Inner' END AS type
FROM Tree A
ORDER BY 1;
하지만 NOT IN, NOT EXISTS, NULL을 마주할 때마다 매번 이렇게 긴 내용을 읽어야 하는 건 매우 비효율적이므로, 공식처럼 암기할 내용을 따로 정리했다.
- NULL
- NULL IS NULL
- SQL은 NULL과의 연산을 UNKNOWN으로 처리한다
- IN, EXISTS
- IN과 EXISTS는 큰 문제 없음. NULL이 섞여도 결과적으로 문제 X
- NOT IN
- NOT IN 은 ≠와 같다.
- NOT IN의 비교대상에 NULL이 포함되면 결과는 아무것도 나오지 않음
- 따라서 NOT IN을 쓸 때는 습관적으로
- 서브쿼리 안에
WHERE 필드명 IS NOT NULL을 쓰거나 - 서브쿼리 뒤에
IS NOT FALSE를 쓰기
- 서브쿼리 안에
- NOT EXISTS
- NOT EXISTS는 결과적으로 외부쿼리에 존재하는 NULL까지 조회 결과에 포함
- 참고로 서브쿼리 안의 NULL 은 아무 상관 없음
느낀점
SQL의 문법은 타 언어들보다 매우 간단하기 때문에 접근도 쉽고, 공부해야 할 내용도 많지 않다고 생각해왔었다.
지금까지 프로그래머스에서 풀었던 문제도 꽤 많이 쌓였고, 모르는 부분도 대체로 새로운 함수(PERCENT_RANK()와 같은..)에 대한 학습이었기 때문에 큰 어려움을 느껴본 적이 없었던 것 같았는데..
NOT IN, NOT EXISTS같은 표준 SQL의 동작을 모르고 있었다는 게 나에게 큰 충격으로 다가왔다.
역시 문법은 기본기가 중요하다는 사실을 다시 한번 절감하며, 지금이라도 이 문제를 확인하고 공부할 수 있었음에 감사하다!
관련 프로그래머스 문제풀이
SELECT - [멸종위기의 대장균 찾기] - LEVEL 5
Reference
https://velog.io/@park2348190/SQL-IN-쿼리에서-Null-값의-영향
https://velog.io/@wogud9675/MySQL-NOT-IN-과-NOT-EXISTS의-차이점
https://day-to-day.tistory.com/22
https://inpa.tistory.com/entry/MYSQL-📚-서브쿼리-연산자-EXISTS-총정리-성능-비교
'SQL' 카테고리의 다른 글
| [프로그래머스] 11주차 MySQL 스터디 (0) | 2024.06.10 |
|---|---|
| [프로그래머스] 10주차 MySQL 스터디 2 (1) | 2024.06.07 |
| [프로그래머스] 10주차 MySQL 스터디 1 (1) | 2024.06.07 |
| GROUP BY - [언어별 개발자 분류하기] _ LEVEL 4 (4) | 2024.06.05 |
| [프로그래머스] 9주차 MySQL 스터디 2 (1) | 2024.06.05 |