
1. SELECT - [특정 형질을 가지는 대장균 찾기] _ LEVEL 1
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
2번 형질을 보유하지 않으면서 1번이나 3번 형질을 보유하고 있는 대장균 개체의 수(COUNT)를 출력하는 SQL 문을 작성해주세요.
1번과 3번 형질을 모두 보유하고 있는 경우도 1번이나 3번 형질을 보유하고 있는 경우에 포함합니다.

[ 정답 쿼리 ]
SELECT COUNT(*) count
FROM ecoli_data
WHERE !(genotype & POW(2,2-1)) AND
(genotype & POW(2,1-1) OR genotype & POW(2,3-1));
[ 풀이 ]
- 비트연산의 성질을 이용해서 풀이
genotype필드는 2진수로 보유 형질을 표현하고 있는데, 그 규칙은 다음과 같다.- 2^0 = 1번 형질
- 2^1 = 2번 형질
- 2^2 = 3번 형질
- 2^(n-1) = n 번 형질
- POW() 함수와 비트연산자(&)를 이용해 위의 형질 조건을 WHERE 절에 걸기
!(genotype & POW(2,2-1)) AND: 2번 형질이 없으면서(genotype & POW(2,1-1) OR genotype & POW(2,3-1)): 1번 또는 3번 형질이 있는 대장균
🌟 2. SELECT - [부모의 형질을 모두 가지는 대장균 찾기] _ LEVEL 2
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
부모의 형질을 모두 보유한 대장균의 ID(ID), 대장균의 형질(GENOTYPE), 부모 대장균의 형질(PARENT_GENOTYPE)을 출력하는 SQL 문을 작성해주세요.
이때 결과는 ID에 대해 오름차순 정렬해주세요.


[ 정답 쿼리 ]
SELECT CHILD.id, CHILD.genotype, PARENT.genotype AS parent_genotype
FROM ecoli_data CHILD
JOIN ecoli_data PARENT ON CHILD.parent_id = PARENT.id
WHERE CHILD.genotype & PARENT.genotype = PARENT.genotype
ORDER BY 1;
[ 풀이 ]
- 부모와 자식의 형질을 비교하기 위해 먼저 테이블 조인(SELF JOIN)
ON CHILD.parent_id = PARENT.id
- 부모의 형질을 모두 보유 : 부모 형질 &(비트연산) 자식 형질 = 부모 형질
🌟🌟🌟 3. SELECT - [대장균의 크기에 따라 분류하기 2] _ LEVEL 3
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
대장균 개체의 크기를 내름차순으로 정렬했을 때 상위 0% ~ 25% 를 'CRITICAL', 26% ~ 50% 를 'HIGH', 51% ~ 75% 를 'MEDIUM', 76% ~ 100% 를 'LOW' 라고 분류합니다. 대장균 개체의 ID(ID) 와 분류된 이름(COLONY_NAME)을 출력하는 SQL 문을 작성해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요 .
※ 단, 총 데이터의 수는 4의 배수이며 같은 사이즈의 대장균 개체가 서로 다른 이름으로 분류되는 경우는 없습니다.

[ 정답 쿼리 ]
-- 풀이 1(내풀이)) ROW_NUMBER() 윈도우함수와 CTE 사용
WITH SUB AS (
SELECT
id
, ROW_NUMBER() OVER (ORDER BY size_of_colony DESC) AS ranking
, COUNT(*) OVER () AS total_counts # 사분위수 계산 시 필요한 전체 데이터 수
FROM ecoli_data
)
SELECT
id
, CASE WHEN ranking <= total_counts / 4 THEN 'CRITICAL' # 0% ~ 25% 를 'CRITICAL'
WHEN ranking <= total_counts * 2 / 4 THEN 'HIGH' # 26% ~ 50% 를 'HIGH'
WHEN ranking <= total_counts * 3 / 4 THEN 'MEDIUM' # 51% ~ 75% 를 'MEDIUM'
WHEN ranking <= total_counts * 4 / 4 THEN 'LOW' # 76% ~ 100% 를 'LOW'로 분류
END AS colony_name
FROM SUB
ORDER BY 1;
-- 풀이 2) PERCENT_RANK() 윈도우함수를 이용한 간단한 풀이
WITH RANK_DATA AS (
SELECT
ID
, PERCENT_RANK() OVER(ORDER BY SIZE_OF_COLONY DESC) SIZE_RANK
FROM
ECOLI_DATA
)
SELECT
ID
, CASE
WHEN SIZE_RANK <= 0.25 THEN 'CRITICAL'
WHEN SIZE_RANK <= 0.50 THEN 'HIGH'
WHEN SIZE_RANK <= 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END COLONY_NAME
FROM
RANK_DATA
ORDER BY
ID
[ 풀이 ]
- 중위수 또는 사분위수와 같이 양적 자료의 분포와 관련된 통계값들을 구하는 문제
- 방법 1)
ROW_NUMBER()이용 : 정렬 기준에 행번호를 붙이고자 할 때 사용 - 방법 2)
PERCENT_RANK()이용 : 윈도우 함수의 일종. 0~1까지의 백분위 순위를 반환
- 방법 1)
PERCENT_RANK()함수는 이번 문제를 통해 처음 알게 되었는데, 이 함수를 이용하면 전체 데이터 수를 구하는 과정을 생략할 수 있다!
4. GROUP BY - [조건에 맞는 사원 정보 조회하기] _ LEVEL 2
HR_DEPARTMENT 테이블은 회사의 부서 정보를 담은 테이블입니다.
HR_EMPLOYEES 테이블은 회사의 사원 정보를 담은 테이블입니다.
HR_GRADE 테이블은 2022년 사원의 평가 정보를 담은 테이블입니다.
HR_DEPARTMENT, HR_EMPLOYEES, HR_GRADE 테이블에서 2022년도 한해 평가 점수가 가장 높은 사원 정보를 조회하려 합니다. 2022년도 평가 점수가 가장 높은 사원들의 점수, 사번, 성명, 직책, 이메일을 조회하는 SQL문을 작성해주세요.
2022년도의 평가 점수는 상,하반기 점수의 합을 의미하고, 평가 점수를 나타내는 컬럼의 이름은 SCORE로 해주세요.

[ 정답 쿼리 ]
SELECT
SUM(score) score
, E.emp_no
, MIN(emp_name) emp_name
, MIN(position) position
, MIN(email) email
FROM hr_employees E
JOIN hr_grade G ON E.emp_no = G.emp_no
GROUP BY E.emp_no
ORDER BY 1 DESC
LIMIT 1;
[ 풀이 ]
- 사원의 정보와 평가 점수의 정보가 담긴
hr_employees테이블과hr_grade테이블을 INNER JOIN - 상하반기의 평가 점수를 합해야 하므로, 사원번호(
emp_no)별로 평가 점수(score)의 합 집계 - GROUP BY에 명시된 필드를 제외하고는 모두 집계함수로 표현되어야 하므로, 성명, 직책, 이메일 등에 집계 함수 적용 후 출력
5. GROUP BY - [연간 평가점수에 해당하는 평가 등급 및 성과금 조회하기] _ LEVEL 4
HR_DEPARTMENT 테이블은 회사의 부서 정보를 담은 테이블입니다.
HR_EMPLOYEES 테이블은 회사의 사원 정보를 담은 테이블입니다.
HR_GRADE 테이블은 2022년 사원의 평가 정보를 담은 테이블입니다.
HR_DEPARTMENT, HR_EMPLOYEES, HR_GRADE 테이블을 이용해 사원별 성과금 정보를 조회하려합니다. 평가 점수별 등급과 등급에 따른 성과금 정보가 아래와 같을 때, 사번, 성명, 평가 등급, 성과금을 조회하는 SQL문을 작성해주세요.
평가등급의 컬럼명은 GRADE로, 성과금의 컬럼명은 BONUS로 해주세요.
결과는 사번 기준으로 오름차순 정렬해주세요.
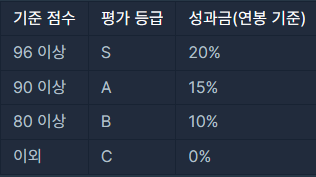

[ 정답 쿼리 ]
SELECT
E.emp_no
, MIN(emp_name) emp_name
, CASE WHEN AVG(score) >= 96 THEN 'S'
WHEN AVG(score) >= 90 THEN 'A'
WHEN AVG(score) >= 80 THEN 'B'
ELSE 'C' END grade
, CASE WHEN AVG(score) >= 96 THEN sal * 0.2
WHEN AVG(score) >= 90 THEN sal * 0.15
WHEN AVG(score) >= 80 THEN sal * 0.1
ELSE 0 END bonus
FROM hr_employees E
JOIN hr_grade G ON E.emp_no = G.emp_no
GROUP BY E.emp_no
ORDER BY 1;
[ 풀이 ]
- 일단 문제 자체에서 기준 점수에 대한 상세한 정보가 부족함
- 여러가지 풀이법으로 제출해본 결과, 해당 문제에서는 사원별 상하반기 평가점수의 평균 점수를 기준으로 평가등급과 성과금을 책정해야 함
GROUP BY와CASE WHEN문을 이용해 조건에 맞는 등급과 성과금을 계산
6. String, Date - [DATETIME에서 DATE로 형 변환] _ LEVEL 2
ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다.
ANIMAL_INS 테이블에 등록된 모든 레코드에 대해, 각 동물의 아이디와 이름, 들어온 날짜를 조회하는 SQL문을 작성해주세요. 이때 결과는 아이디 순으로 조회해야 합니다.
※ 시각(시-분-초)을 제외한 날짜(년-월-일)만 보여주세요.

[ 정답 쿼리 ]
SELECT animal_id, name, DATE_FORMAT(datetime, '%Y-%m-%d') `날짜`
FROM animal_ins
ORDER BY 1;
[ 풀이 ]
- 날짜를 출력하는 데이터의 포맷을 조절하는 간단한 문제
DATE_FORMAT(datetime, '%Y-%m-%d'),SUBSTRING(datetime, 1, 10),LEFT(datetime, 10)세 가지 방법 모두 정답으로 인정

'SQL' 카테고리의 다른 글
| NOT IN, NOT EXISTS와 NULL (1) | 2024.06.07 |
|---|---|
| [프로그래머스] 10주차 MySQL 스터디 2 (1) | 2024.06.07 |
| GROUP BY - [언어별 개발자 분류하기] _ LEVEL 4 (4) | 2024.06.05 |
| [프로그래머스] 9주차 MySQL 스터디 2 (1) | 2024.06.05 |
| [프로그래머스] 9주차 MySQL 스터디 1 (0) | 2024.06.05 |