
[DAY 6, 8] 실무 엑셀 데이터 분석& 기초 수학/통계 시작하기 - 이동훈 강사님
지난 주 EDA에 이어서..
2. EDA
- EDA는 데이터 분석 과정 전체에서 필요할 때마다 수시로 사용되는 과정
- 데이터 분석 도구
- 꼭 이름을 같이 잡고 첫째 행 이름표 사용 체크
- 평균보다 중앙값이 이상치에 강건하다(ROBUST)
- 데이터에 대해 합계, 평균, 최대, 최소 정도는 그래도 알자!
- 피벗 테이블 : RAW DATA가 어느 정도 정리된 형태라면, 데이터 내 어딘가에만 클릭을 해 둔 채로 > 삽입 > 제일 첫 번째에 있는 피벗테이블
- 피벗테이블에서 제일 중요한 것은 행, 열, 값을 결정하는 것이 거의 90%
- 문자데이터(ex. category)의 경우는 클릭 시 자동으로 행으로, 숫자 데이터(ex. sales)는 자동으로 내용으로 간다.
- 여러 가지 형태로 값을 보고 싶을 때 : 똑같은 숫자 항목(여기서는 SALES)를 한번 더 값에 끌어서 놓고 값 필드설정>값 표시형식>열합계비율(열의 항목에 따른 퍼센티지 표시)
- fancy한 filter 쓰기 : 피벗 테이블 도구 > 분석 > 슬라이서 삽입
- 데이터를 처음 볼 때 하나씩 행에 넣어보면서 category나 데이터의 형태를 한번 확인하기
- 단변량, 다변량(cross) 형태로 쫙 살펴보기


- 결측치와 이상치 탐색
- 결측치(Missing Value) : NA, NaN, Null, (빈칸)
- 결측치 처리방법
| 1제거(데이터의 사이즈와 상황에 따라 데이터의 손실이나 통계적 편향이 생길 수 있음) 2치환(평균, 중앙값, 최빈값 등으로 대체 가능하나, 단순대체는 편향을 높일 수 있음) 3모델 기반 처리(변수의 특성에 따라 Knn, Polyregression 등의 방법을 활용해 대체) |
- 결측치 처리에 있어서, 데이터에 대한 도메인 지식이 충분히 있어야 하고, 데이터의 성격에 따라 적용할 처리 방법이 달라진다.
- 이상치(outlier)
- cf) 정규분포 : 평균을 중심으로 가까운 곳에 값이 있을 확률이 높고, 멀어질수록 값이 있을 확률이 낮아지는 분포 -> 사회, 자연현상들이 실제로 정규분포의 형태를 띠고 있기 때문에 중요
- 이상치는 반드시 제거해야 하는가? 반드시는 X. 금액이 확 뛰는 고객(잠재적 vip)일 수 있음
- z-score : 자료가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 지표
| 방법1) 일반적으로 바깥의 범위의 데이터(극단적인 값) -> z-score가 +-3인 범위(관습적 범위이니, 데이터에 따라 달라질 수 있음) 방법2) 사분위수 이용. (Box Plot 이용) 1Q – 1.5 * IQR(= 3Q – 1Q) 미만// 3Q + 1.5 * IQR(= 3Q – 1Q) 초과 |
- 삽입>히스토그램>상자그림(excel 2016 이상에서)
- 통계학적인 이상치가 현실에서도 무조건 이상치라고 할 수는 없다는 걸 명심
- 상관 분석과 산점도
- 상관계수 : 일반적으로 피어슨 상관 계수 사용. r이 +-0.7 바깥이면 강한 상관관계. 중요한 건 선형 관계를 의미
- 가장 주의할 점 : 상관관계와 인과관계는 다르다!(인과관계가 아예 없을 수도 있음)
- 그럼에도 상관관계를 분석 단계에서 많이 보는 이유는, 후보군을 추려서 인과관계를 확인해보기 위해서(역명제는 참이기 때문에)
- 데이터 분석의 상관계수 분석 후 조건부 서식으로 색깔 지정
- tip : 1차적으로 서식 적용 후 만약 값들이 비슷해서 구분이 잘 가지 않는다면, 서식의 범위를 조정하기(구분을 뚜렷하게!) ex. 예제의 경우 음의 값이 없으며 상관계수의 평균이 0.65로 상당히 높은 편이므로, 3가지 색을 2가지로 바꾸고 서식의 최솟값을 0.65로 잡기
- 산점도 그리기 : 엑셀에서는 산점도는 왼쪽부터 x,y 순으로 인식하기 때문에, 빈차트를 먼저 만든 뒤에 데이터 추가를 하기(레이블 빼고 데이터만)
3. 데이터 전처리
- 데이터 분석 과정 중 가장 많은 시간과 비용이 필요한 과정(60%~80%)
- Garbage in, garbage out!
- 데이터 분류
- IF함수 사용 : ex. IF(A1>=90, “합격”, “불합격”), IF함수 n번 중첩 시 (n+1)개로 구분
- 나이, 경력년수 등 숫자 데이터는 카테고리화 해줄 수 있음
- 데이터 추출
- VLOOKUP 함수 : 기준열(Vertical)을 중심으로 일정 거리에 떨어진 정보를 찾는 함수
- VLOOKUP의 기준열의 왼쪽에 있는 값은 1) 기준열을 옮기거나, 2) INDEX,MATCH함수로 극복
- VLOOKUP 함수를 적용할 DATA_ARRAY가 데이터 추가 가능성이 있는 경우, 범위를 열로 잡기!!
- INDEX, MATCH 함수와 궁합이 좋음 (MATCH의 리턴값이 인덱스임)
- 함수를 여러 개 쓸 때 한 번에 다 쓰려고 하지말기
- 데이터 계산
- COUNT 계열 함수
- COUNT() : 숫자 데이터 세기
- COUNTA() : 빈칸을 제외한 모든 데이터 세기
- COUNTIFS() 함수
| - COUNTIFS()의 조건? -> 숫자만 쓸 때는 그대로, 불완전한 부등식이나 문자일 때는 “”를 꼭 붙여서 - 같지 않음 = “<>Artist” , 빈칸 ‘<>“”’ - 해당 셀을 참조해서 조건을 걸고 싶을 때는.. : 일단 해당 셀의 서식을 바꾸고(~이상, 이하로 보이게) > “>=”&해당셀참조 >&를 이용해서 문자열을 연결!(“”안에서는 참조가 먹히지 않으므로) - 빈칸이 아닌 셀을 세고 싶을 때는 “<>”&“” 이렇게! - COUNTBLANK() 함수는 범위를 열로 잡을 수 없다 >엑셀의 자동 스크롤 이용 - COUNTA(범위) - 1 : 보통 레이블이나 단위 적힌거 뺄 때(엄청 자주 씀) - 범위는 COUNTBLANK 빼고는 전부 열로 잡는다 |
- SUMIFS 함수 : 조건범위와 합계범위의 높이를 맞춰주는 게 중요!
- 위계가 있어서 띄엄띄엄 붙여넣기 해야하는 경우: 행을 먼저 만들어서 복사한 뒤 > 첫 셀들만 끌어서 붙여넣기!
- 함수 vs 피벗 테이블 : 데이터가 갱신되는 성격이 있다면 함수. 보고용으로 올라갈 친구도 함수(피벗 테이블은 주로 중간 단계에서 확인이나 분석이 필요한 경우)
- 텍스트 데이터 처리
- FIND 함수: 찾는 값이 없으면 value error발생!(IFERROR로 감싸기)
- 텍스트 베리에이션 : 전체의 80퍼센트 정도만 나와도 ok(재밌+재밋 = 약 20,000개 + 핵잼 8개가 의미가 있냐는 거지)
- 파이썬 NLP등을 사용하면 훨씬 더 정확한 분석 가능
- cf ) SEARCH함수는 대소문자 구분 안하는 버전
- 엑셀의 한 셀에 여러 가지 데이터가 들어가 있는 경우 쪼갤 필요가 있다(LEFT, RIGHT, MID함수 이용) -> 이때 쪼갤 데이터가 다른 글자수이지만, 동일 SEPERATOR로 구분되어 있을 경우 FIND함수와 결합하여 사용 가능
- tip : 텍스트 나누기 기능(데이터 탭)이 따로 있음!(날짜는 year, month, day함수로 나누기) - raw data 훼손 주의 + 공백에서 ‘연속된 구분기호를 하나로 처리’
- 중복된 항목 제거하기 : 역시 raw data 훼손 주의, 표 만들 때 레이블 만들기 용이
- 필터(CTRL+SHIFT+L) : ALT + A + T, ALT + D + F + F. 텍스트, 숫자 필터링 가능. 색필터 가능. 정렬과 필터도 사용자지정 기준으로 가능
- (CF . 엑셀은 마지막으로 실행한 기능을 기억하고 있다 F4키로 실행가능(EX. 색 채우기))
- 데이터 유효성 검사 : 데이터 범위 설정 > 데이터 유효성 검사(데이터탭) > 조건 설정 후 > 잘못된 데이터 적용
- (잘못된 입력 방지) : 공유폴더나 중요한 폴더의 입력을 제한할 때
- 데이터 유효성 검사는 목록 드롭다운 용으로 훨씬 잘쓴다.(거의 99프로)
4. 데이터 분석/모델링
- 통계학 : 표본 정보로부터 모집당의 특성을 추론하는 방법론을 연구하는 학문
- 맹신은 금물
- 기술 통계/추론 통계
- 가설 검정
| - 귀무가설(영가설) - 기본적으로 참으로 추정되며 처음부터 버릴 것으로 예상하는 가설 - 대립가설(연구가설) - 연구로서 밝히고자 하는 가설 - p-value(유의 확률) : 귀무가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 ‘같거나 더 극단적인’ 통계치가 관측될 확률 |
- p–value를 사용할 때 주의사항 : 관계의 강도나 크기 등을 설명하는 것은 아님 ->상관계수나 결정계수 등의 지표를 함께 활용해 분석 결과를 더 정확히 표현할 수 있음
1) t-test
- 두 집단(혹은 한 집단의 전후)의 평균에 통계적으로 유의미한 차이가 있는지를 검정
- 순서
| 1. f검정(귀무가설 : 등분산이다)의 결과에 따라 t-test의 종류가 갈림 –> p-value가 0.05보다 커서 귀무가설을 기각하지 못하면 등분산 t-test로 그 외에는 이분산 t-test 2. t-test(귀무가설 : 두 집단의 평균에 유의미한 차이가 없다) |
<엑셀실습>
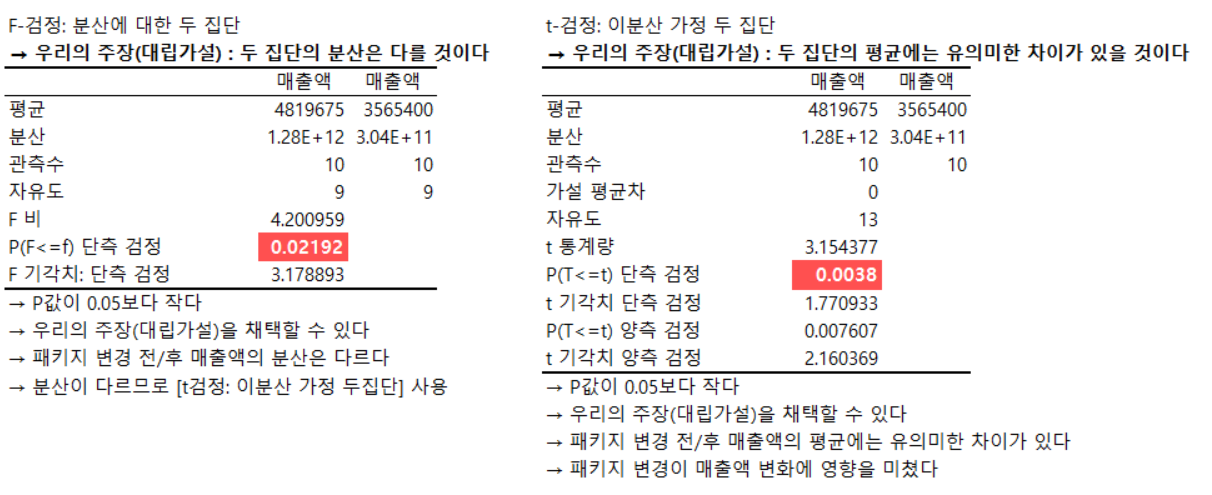
- 실습 결과를 보면 유의미한 결과이긴 하지만, 평균을 봤을 때 평균은 오히려 떨어졌다.
- 즉 유의미한 차이가 있다는 것이 곧 긍정적인 결과라는 뜻은 아니라는 점 유의하기
2) 회귀분석(Regression analysis)
- 두 개 이상의 연속형 변수(수치)인 종속 변수와 독립 변수 간의 관계를 파악하는 분석
- y(종속변수) = ax(독립변수) + b
- 최소제곱법 : 오차제곱합이 최소가 되는 선형회귀식을 찾는 것
<단순 선형 회귀 분석의 평가와 해석>

| ① r^2= 결정계수 = 직선이 데이터를 얼마나 잘 설명하는지를 나타내는 설명력(0-1) ② 유의한 F(귀무가설 : 모형이 무의미하다) <0.05 : 모델이 유의미하다 ③ Y절편, X1의 계수 : b, a값( 여기서도 p값을 보는데, 만약 절편의 p값이 유의수준 0.05하에서 귀무가설을 기각하는 수준이라면, 절편이 없는 모델로 다시 피팅하기 |
<다중 선형 회귀 분석의 평가와 해석>

| ① adjusted r^2= 결정계수 = 직선이 데이터를 얼마나 잘 설명하는지를 나타내는 설명력(0-1) -> 다른 독립변수의 영향력을 조정 ② 유의한 F(귀무가설 : 모형이 무의미하다) <0.05 : 모델이 유의미하다 ③ p-값 (귀무가설 : 각각의 독립변수가 종속변수에 영향을 주지 않는다) |
| <선형 회귀 Process> |
| 00. 상관분석 – 상관 관계가 강한 변수 도출 01. 다중 선형회귀분석 – 모든 변수로 02. 다중 선형회귀분석 – 유의미한 변수들로 03. 단순 선형회귀분석 – 유의미한 변수들로 각각 |
3) 시계열 분석
- 시간의 흐름에 따라 발생된 데이터를 분석하는 기법
- 정상성 : 추세나 계절성을 가지고 있지 않으며, 관측된 시간에 무관한 성질

- 비정상 시계열 데이터의 정상 시계열 데이터화 : 대부분의 시계열 데이터는 비정상 시계열 데이터인데, 비정상 시계열 데이터인 상태로는 분석이 어렵기 때문에 차분이나 다른 방법을 활용해 비정상 시계열 데이터를 정상 시계열 데이터로 변환해 분석하기도 함
| <시계열 – 지수 평활법> |
| 지수 평활법 : 현재 시점에 가까운 시계열 자료에 큰 가중치를 주고, 과거 시계열 데이터일수록 작은 가중치를 주어 미래 시계열 데이터를 예측하는 기법 - FORECAST.ETS : 엑셀에서 사용할 수 있는 지수 평활법 관련 예측 함수 =FORECAST.ETS(target_date, values, timeline, [계절성주기], [누락데이터처리], [중복시계열처리]) |
이 분석이 끝이 아니고, 꼭 실무자의 insight가 더해져야 한다. |
| - 시각화 tip : (년도 – 월)을 예쁘게 표현하기 위해서는 년도는 한번만 셀에 기입(카테고리화) - 그래프가 이어질 수 있도록, 예측치 바로 앞 값을 예측 그래프 수치의 시작점으로 복사해오기 - 예측 그래프는 실선보다는 점선으로! |


4) 머신러닝
- 인공지능 > 머신러닝 > 딥러닝
- 머신러닝(기계학습, Machine Learning) : 컴퓨터가 어떤 작업(T, task)을 하는데 있어서 경험(E, experience)으로부터 학습하여 성능(P, Performance)을 향상시키는 학문
| ① 지도 학습(Supervised Learning) - 지도 학습은 정답(Y)이 있는 데이터를 활용해 데이터를 학습하고, 학습한 모델이 얼마나 정답을 정확하게 맞추는지 평가하는 학습 - 분류, 회귀 문제들을 해결할 수 있음 - (train, test) ② 비지도 학습(Unsupervised Learning) - 비지도 학습은 정답(Y)이 없는 데이터를 활용해 데이터를 학습 - 데이터가 어떻게 구성되어 있는지, 혹은 어떻게 분류될 수 있는지에 대한 문제 해결 ex. clustering, 차원축소 ③ 강화 학습(Reinforcement Learning) - 에이전트(학습 시스템)가 취한 행동에 대해 보상 또는 벌점을 주어 가장 큰 보상을 받는 방향으로 유도하는 방법 - 가장 큰 보상을 얻기 위해 에이전트가 해야 할 행동을 선택하는 방법을 정의하게 되는데 이를 ‘정책’이라고 함 |
5. 데이터 시각화
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정
- 나이팅게일의 로즈 다이어그램
- 데이터 시각화는 도구(Tool)가 아니라 전략(Strategy)이다!
- 차트를 그릴 때 고민해야하는 3가지?
| 차트란 숫자의 다른 표현! ① 어떤 숫자 차트를 그릴 것인가? ② 어떤 차트가 숫자를 가장 잘 설명하는가? ③ 차트를 어떻게 디자인하는 게 가장 효과적인가?(디자인이란 성능을 끌어올려 주는 것) |

* 막대그래프
- 그릴 때 레이블을 같이 잡는 습관
- 엑셀 셀 눈금 없애기 : 보기 탭 > 눈금 선
- 조건부서식 : 가장 좋은 점(유동적 데이터에 맞게 서식이 움직인다!)
- KPI 지표를 표현하는 데에도 탁월
* Interactive Dashboard
- 피벗 테이블의 데이터로 차트를 그리면 무조건 피벗 차트
- 한 개의 피벗 테이블에서 모든 걸 다 연동하면 응용이 힘들어짐
- 슬라이서와 그래프를 분리해서 만든 뒤, 연결(슬라이서 오른쪽 마우스 > 보고서 연결)
- 피벗 테이블이 많아지면 헷갈리니까, 피벗 테이블 설정에서 이름을 제대로 설정해놓기
6. 프로젝트 실습 예제
- 분석이 꼭 거창한 거시적 목표와 화려한 기술로 이루어지는 건 아니다!
① nc 소프트 리니지 구글 스토어 리뷰 크롤링
| 1. (과금, 현질, 돈)에 대한 말이 대부분 > 적어도 한 번 이상의 언급이 있다면 ‘과금불만유저’로 정의함(SUM(IFERROR(FIND))) 2. 그래픽, 질문(?), 장애 등의 키워드도 동일 진행 3. 평점별로 비율(익명임을 자각하기) > 다른 변수와 크로스로 |
② 코로나 확진자 현황
| 1. raw data가 개판 – 날짜도 서식이 안맞고, 데이터도 누적으로 되어있음 2. vlookup으로 값을 불러와서 누적값을 펼쳐주려면 중복되지 않는 key 열이 필요 ->날짜 & 지역명으로 새로 생성 3. 버블차트를 지도위에 나타내기 4. (추가)날짜 데이터는 이렇게 바꾸면 됨 : =TEXT(D4,"0000-00-00") > 서식 날짜로 바꾸기 |
[DAY 7, 9] 깊이 있는 데이터 분석을 위한 기초 수학/통계(온라인)
1. 통계, 엑셀 데이터 탐색 시작하기
- 통계학 : 불확실성 속에서 정보를 찾아내는 학문
- OKR, KPI 등 지표를 통한 방법론, growth marketing(performance marketing)
- 데이터 분석 단계 : 분석 기획 – 수집 및 정제 – 분석 & 모델링 – 결론 도출 – 활용
| 1. 비즈니스적으로 어떤 것을 이루고자 하는지 2. 수집된 데이터의 정합성, 무결성 등을 검증 3. EDA, 모델링 4. 도메인에 따라, 비즈니스적 요구에 따라 성능의 기준은 달라짐 5. 시스템 구현, 비즈니스 인사이트, 서비스에 활용 |
- EDA : 기초적인 통계 개념으로 데이터 전체를 파악, 전처리의 방향성 제시, 데이터의 형질에 대한 도메인 개념 축적
- EDA를 통해 전처리의 방향성을 잡을 수 있음
- ex. 타이타닉 데이터의 EDA : 어떤 데이터로 분석할지, 결측치는 어떻게 처리할지, 분석의 방향은 어떻게 잡을지를 생각할 수 있음
<공분산, 상관행렬 실습>
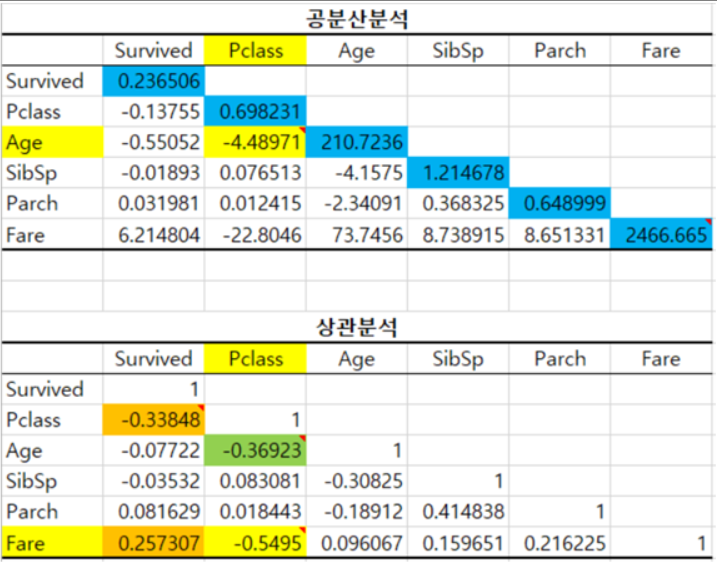
- 공분산의 부호 : 양/음의 상관관계를 나타냄 ex. Fare, survived : 요금을 많이 낼수록 생존 확률이 높은 양의 상관관계를 보인다 - 공분산의 크기 : (주의) 크기가 크다고 상관관계가 큰 것은 아니다(말 그대로 분산은 데이터의 베이레이션이 그대로 반영되어 있기 때문에 비교하기 위해서는 이를 스케일 해줄 필요가 있음) - 상관분석 : survvived 가 pclass와 fare와의 상관관계가 높은데, 이는 pclass와 fare끼리의 상관도가 높기 때문이다 나이가 많을수록 부의 축적이 높을 것이다, 돈을 많이 내면 좋은 좌석으로 갈 것이다 등의 파악을 해볼 수 있음 |
2. 엑셀만 알아도 시작할 수 있는 데이터 탐색
1) 데이터 탐색 사례
| ① 대푯값을 통한 데이터 탐색 : 통계량을 통해 집단의 특성을 파악(데이터에 대한 직관을 얻기 좋음) ② 차트를 통한 데이터 탐색 : 바이올린 차트를 통해 분포를 확인(주로 인구통계), 요금의 분포, 왜도의 비대칭을 파악(outlier 값을 확인) -> 분포와 함께 ①대푯값을 같이 파악하기(ex. 비대칭성이 높은 데이터는 평균보다는 중위값) ③ 상관관계를 통한 데이터 탐색 : iris 데이터. 독립적인 변수일 것 같아도 상관관계 시각화를 통해 보면 아닌 경우도 많다, 의미있는 값을 찾는 것도 중요하지만, 의미 없는 데이터를 제거하는 것도 매우 중요(효율성, 차원축소) ④ 결측치, 이상치를 통한 데이터 탐색 : boxplot 파악(전체적으로 파악 후 비슷한 변수끼리 따로 찍어보기) -> 이상치에 대한 고민도 해보기(무조건 이상치는 아님). iris 박스플랏을 보면 확실히 setosa가 다른 종들에 비해 동떨어져있는 것을 확인 가능 outlier를 제거하고 학습을 해본다던지, 도메인에 따라 결정하기 |
2) 데이터 탐색과 통계 필요성
- 기술통계 vs 추론통계(추출한 표본의 통계량 관찰 및 분석 기법을 활용하여 모집단을 추론, p-value 등을 활용하여 추론의 신뢰도 확보)
- 데이터에 맞는 적절한 통계 기법을 활용할 수 있는 능력이 필요 -> 데이터로부터 올바른 정보를 얻어내는 과정
- ex. 정규성 검정을 통해 정규 분포를 따르는지 아닌지를 판단 후 분포에 따라 사용할 수 있는 통계적 방법론이 달라짐
3) 차트로 엑셀 데이터 쉽게 탐색하기
① 히스토그램 : 피벗 테이블과 차트 이용
- tips : 압도적 비율을 차지하는 카테고리가 존재할 경우, 제외 후 분석 해보기

② 산점도 : iris dataset( 더 쉽게 그리는 방법은 없을까?)
③ 박스플랏 : titanic dataset의 Fare(500이상의 값이 하나 있음 – 이상치인가?) > pclass와 fare의 상관관계가 높은 것을 이전에 확인했으므로 pclass별 boxplot 확인 > 이상치로 의심되는 500 이상의 값은 1등석인 것으로 확인됨 > 그래도 너무 값이 튀는 것 같다고 판단이 된다면 이상치로 잡기( 포인트는 이런 플로우로 확인을 했다는 점 )
3. 비전공자를 위한 기초통계
1) 고등학교 기초통계
| 자료의 종류 : 범주형 자료(categorical) vs 양적 자료(수치 표현 가능) - 범주형 : 명목형(혈액형), 순서형(만족도) - 양적 : 구간형(비교는 의미가 있으나, 비율이나 절대값은 의미가 없다. 기온, 년도), 비율형(키, 몸무게) - 양적 자료의 또 다른 분류 : 이산형(동전 10개 앞면 분포), 연속형(키, 몸무게) - 이산형 확률 분포 : 정확한 값이 나옴 → 확률분포표 - 연속형 확률 분포 : 구간에 속하는 확률 값을 구함 → 확률밀도함수 |
2) 기술통계
① 중심경향성
- 최빈값 : 주로 범주형 자료에서 사용
- 중앙값 : 순서형 자료의 대푯값으로 적합. robust from 이상치
- 평균값
| 산술평균 : 주로 연속형 자료의 대푯값 가중평균(Weighted) : 자료의 중요도에 따라 가중치를 부여한 평균 기하평균(Geometric) : 성장률, 주가 상승률 등 이전 시점에 대한 비율에 대한 평균을 구할 때 유용 |
② 퍼짐정도
- 분산 : 편차 제곱의 평균
- 표준편차 : 편차의 평균과 비슷한 개념
- 범위(range) : 최대값 – 최소값. 범위 내의 분포에 대한 정보는 알 수 없음. 극단치의 영향을 많이 받음
- IQR : (3Q-1Q). 한쪽으로 치우친 분포의 퍼짐정도를 확인할 때 유용.
③ 왜도

- 왜도(skewness) : 비대칭성을 나타내는 지표. 기준을 0으로 +-3 이내면 대체로 대칭적이라고 보기도 함
④ 첨도(kurtosis) : 평균을 중심으로 얼마나 가까이 몰려있는지 나타내는 지표. 값이 클수록 더 뾰족한 분포. 이상치에 영향을 많이 받음. +-8 이내면 정규분포랑 비슷하다고 보기도 함
3) 회귀분석, 공분산, 상관계수
① 회귀분석(Regression analysis)
- 결과를 설명하기 위해서 하나의 변수만 영향을 주는 경우는 거의 없음
- 결과를 종속변수, 종속변수를 설명하기 위한 변수를 독립변수
- 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석방법
- 장점 : 종속변수에 영향을 미치는 독립변수의 영향력을 판단가능
- 주의점 : 인과관계를 설명해주지는 못한다.(상관분석이랑 같은 맥락) ->변수를 잘 설정해서 시간의 선후관계가 있다거나 하면 모르겠지만, 그게 아니면 인과관계를 설명할 수는 없다는 얘기
② 공분산
- 2개의 확률변수의 선형관계를 나타내는 값
- 봐야할 점 : 부호
- 주의점 : {두 변수가 독립변수일 때 → 공분산 0} 역은 성립하지 않음!!!!!
③ 상관계수
- 공분산의 크기는 의미가 없음(변수의 스케일에 따라 공분산도 천차만별이기 때문)
- 공분산을 비교 가능하도록 표준화하자! → 상관계수의 등장
- 일반적으로 말하는 상관계수는 피어슨 상관계수
- 범위 : [-1, 1]
- (상황에 따라 다르지만) 절댓값이 0.5~0.7 이상이면 강한 상관관계를 가진다고 봄
4. 엑셀에 기술통계 기초 적용해보기
1) 대푯값으로 데이터 분포 파악하기

- 피벗차트를 이용해서 예측했던 분포의 모양도 볼 수 있음(FLOOR.MATH($A2/5)*5 로 데이터 계급 추상화)
2) 이상치 탐지
- IQR 활용 : 데이터의 분포가 치우쳐 있을 때 쓰는 이상치 탐지기법
- Z-score 활용 : 분포가 정규분포를 따르는지가 먼저 전제되어야 함(정규성 검정이나, 못해도 히스토그램이라도 살펴보는 전과정이 필요)
- Box-Plot 활용 : 엑셀에서 박스플랏의 위아래 선이 (Q1 - 1.5 * IQR, Q3 + 1.5 * IQR)
- 데이터 레이블 추가 후 (Q1 - 1.5 * IQR, Q3 + 1.5 * IQR) 값을 레이블에서 확인 가능
3) 두 변수의 상관관계 분석하기
- 산점도 활용 및 회귀선 찾기

- 공분산, 상관계수 측정 및 회귀선 비교하기 : 데이터의 분포와 수치를 꼭 복합적으로 확인할 필요가 있다

5. 추론통계 맛보기 & 공공데이터 탐색해보기
1) 추론통계
① 난수 생성하기
- rand()함수로 생성 후 값만 복사하기
- 엑셀 함수 randarray([행], [열], [최대], [최소], [정수여부])로 원하는 개수만큼의 랜덤 value를 한 번에 생성할 수 있다(
엑셀 2016 이상 버전 要) - 데이터 분석 도구 이용하여 난수 생성 가능
② 엑셀에서 모분산, 표본분산을 구하는 함수 : .P / .S의 차이가 있으니 상황에 따라 잘 구분해서 쓸 것
③ 정규분포 관련 함수
| - NORM.DIST(x, mean, standard_dev, cumulative) : 지정한 평균과 표준편차에 의거한 정규분포 값 도출. cumulative=TRUE일 때 누적 분포함수 도출. - NORM.INV(probabiliity, mean, standard_dev) : ~ 정규누적분포의 역함수 값 도출 - NORM.S.DIST(z, cumulative) : 표준정규분포에서 ~ - NORM.S.INV(probabiliity) : 표준정규분포에서 ~ |
- 정규분포에서 random sample 추출 : 데이터 분석 도구에서 난수 추출 > 분포를 정규분포로 설정하기 → 많은 표본을 추출해서 직접 표본 평균, 표본 표준편차 구해보기
④ t분포 관련 함수
- t분포의 쓰임새 : 표본의 개수가 30개가 안될 때, 적은 표본으로 분석
- t분포의 정규분포 근사 : 자유도(degree of freedom)가 커질수록 정규분포에 가까워진다.(n>30)
- T.DIST(x, deg_freedom, cumulative)
- 정규분포에 비해 퍼져있는 종모양
⑤ 이항분포 시각화, 이항분포의 정규분포 근사
- 확률이 p인 베르누이 시행을 N번 독립시행 했을 때 X=n일 분포
- BINOM.DIST(number_s(x), trials(N), probability_s(p), cumulative) : 이항분포를 따르는 확률 도출
- 이항분포와 정규분포의 근사를 시각적으로 비교하기 위해서는 확률 누적 분포로 확인
2) 중심극한정리
- 모집단에서 크기가 N인 가능한 모든 무작위 표본들을 추출 시, N>=30 으로 N이 커짐에 따라 그 표본들의 평균의 분포는 정규분포에 근사한다.
- cf) 큰수(대수)의 법칙 : 표본의 크기가 충분히 크다면 이 표본의 평균이 모집단의 평균에 가까워진다.
3) 분포의 모양과 추론통계
- 추론 통계 : 모집단으로 추출된 표본으로부터 모수를 추정하는 과정
- 가설 검정
| - 독립성 검정 : 두 변수 사이에 상관관계가 있는지 - 샤피로 윌크 검정 : 표본이 정규분포로 추출된 것인지 - 카이제곱 검정 : 데이터가 특정 분포를 따르는지 - 콜모고로프 스미르노프 검정(K-S검정) : 두 데이터가 차이가 있는지(같은 모집단으로부터 추출된 건지) |
- 결국에는 위와 같은 가설 검정이 데이터의 분석 방향을 좌지우지하기 때문에, 추론통계를 이해하는 것이 중요하다고 볼 수 있음
4) 공공 데이터 셋 탐색하기
- 공공 데이터 포털(https://www.data.go.kr/) : 테마별, 카테고리별 분류
- ex. 국민연금공단_국민연금 가입 사업장 내역.csv
< 국민연금공단_국민연금 가입 사업장 내역 탐색(엑셀) 실습>
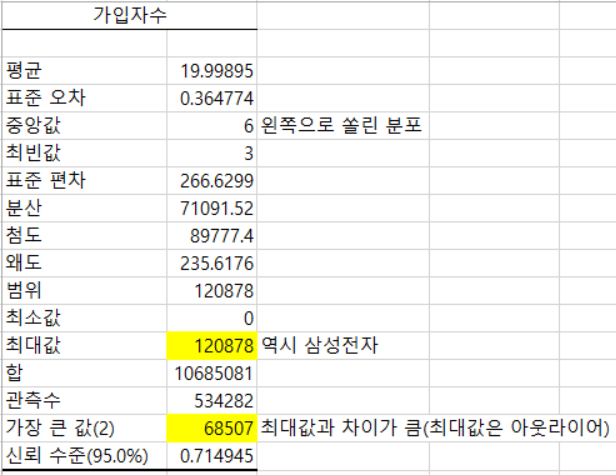
| 가입자 수의 기술통계를 확인해 보았음 대부분 소규모 사업장인 것 같음 최대값은 아웃라이어 만약 B2B사업을 고려한다면 대상을 소규모 사업장으로 한다면 풀을 넓힐 수 있을 것 피벗 테이블로 이변량 관계도 살펴볼 것 |


| 상관분석의 결과 가입자수와 신규 취득자수가 양의 상관관계가 있다고 보여짐(아마 규모가 큰 회사라면, 그만큼 신규를 많이 뽑기 때문에?) 신규 취득자수와 상실 가입자수 사이의 상관관계도 보여짐 |

| 피벗 테이블로 ‘법정동주소광역시시도코드’별 가입자수와 당월고지금액을 확인 상위 3곳은 확인해보니 서울, 경기도, 경상남도 순이었고, 서울과 경기도의 퍼센티지가 전체의 절반 이상을 차지하고 있음 |
이번주 느낀 점과 생각
- 복습할 양이 엄두가 나지 않을 정도로 불어난다
- 통계를 예전에 배웠었는데, 기억이 거의 나지 않으니까 현타가 왔다. 예전 공부했던 자료들이라도 꺼내서 좀 봐야하나 싶다(통계를 어느 정도로 봐야하는 지 감이 안온다)
- 생각보다 기억의 휘발이 빠르고, 잊어버리는 내용은 다시 봐도 얼마 안가서 또 잊어버리는 듯 하다. - 이래서 암기가 필요한 부분도 확실히 있다고 생각이 든다
- 기록을 남기는 건 정말 중요하다는 걸 매번 느낀다(예전에 파이썬 공부할 때 시간 들여 남겨놨던 포스팅이 지금 이렇게 도움이 될 줄 누가 알았을까!)
- 직접 말로 해보고, 글로 써보고 나의 언어로 표현하고 익혀야 몸과 머리에 잘 배는 것 같다(그런데 그게 막상 하려면 잘 안된다)
- 11.3에 들은 온라인 DS 강의에서 강사님이 내용 전달도 잘하시고, 노션과 구글 콜랩을 이용해 강의를 하시는 걸 보고 많은 생각이 들었다. 어떤 학문을 익히는 것도 중요하지만, 그 학문을 내 머리속에 나만 이해되게 가지고 있는 것은 사회에서의 효용이 많이 떨어진다는 것을 느끼는 요즘이다. 엑셀 강사님도 말씀하셨지만, 내가 아는 걸 남에게 효과적으로 전달하는 게 정말 능력인 것 같기도 하다.(물론 공부와 pt 능력의 밸런스가 필요한 건 당연하지만.)
- 공부하면서 한 번은 찾아봐야겠다 싶은 통계 지식과, 파이썬 지식을 메모해 놨다. 평일에는 진도에 치여 메모장만 늘어나는데,, 주말에 한 번 찾아보고 따로 포스팅을 해야겠다. 가령 파이썬의 sequence와 iterable의 차이점은 내가 작년에 공부할 때도 헷갈렸고, 공부하고 한달 뒤에도 헷갈려서 여러 번 찾아보았었는데, 결국 지금도 헷갈린다. 이런 부분은 한 번더 확실한 포스팅이나, 암기가 필요한 것 같다. - 앞으로는 메모장 내용은 따로 포스팅으로 남기기!
- 내일부터는 파이썬 강의가 시작된다. 이제 워밍업은 끝났고 본격적으로 들어가게 되는데, 나만의 공부 루틴을 만드는 게 중요하다고 생각이 든다.
'패스트캠퍼스 학습일지' 카테고리의 다른 글
| [패스트캠퍼스 DA 부트캠프 11기]7주차 학습 (0) | 2023.12.07 |
|---|---|
| [패스트캠퍼스 DA 부트캠프 11기]6주차 학습 (1) | 2023.11.30 |
| [패스트캠퍼스 DA 부트캠프 11기]4주차 학습 (0) | 2023.11.17 |
| [패스트캠퍼스 DA 부트캠프 11기]3주차 학습 (3) | 2023.11.09 |
| [패스트캠퍼스 DA 부트캠프 11기]1주차 학습 (1) | 2023.10.26 |