
지난 2주 간 SQL 프로젝트를 하느라, 학습한 내용들을 노션에만 담아놓고, 정리하지 못했다.
지금 이 글을 작성하는 현재는 SQL 프로젝트는 마무리하고 새로운 시각화 툴인 Tableau를 배우고 있다!
사실 시각화 툴은 처음이라 좀 걱정했는데, 생각보다 너무 재밌다...!
이번주까지는 SQL을 마저 정리하고, 다음주부터 Tableau 관련 정리와 공부내용들을 올려볼 예정이다.
💵 1. 서비스 이해 기본
USE fastcampus;
SHOW TABLES;
SELECT * FROM tbl_customer LIMIT 1;
SELECT * FROM tbl_purchase LIMIT 1;
SELECT * FROM tbl_visit LIMIT 1;
# Q1 : 2020년 7월의 총 Revenue를 구하기
DESC tbl_purchase;
SELECT SUM(price)
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01' # TEXT여도 상관 없음
AND purchased_at < '2020-08-01';
# 21,060,206,300원MAU: Monthly Active Users; 월 활성 유저- ‘활성’을 어떻게 정의하느냐에 따라 다르겠지만, 해당 문제에서는 tbl_visit에서 방문 유무를 기준으로 삼음
DESC tbl_visit;
SELECT COUNT(DISTINCT customer_id) FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01';
# 16414명- 7월의 구매유저 수 / 전체 활성유저
SELECT COUNT(DISTINCT customer_id)
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'; # 11174
SELECT COUNT(DISTINCT customer_id)
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
AND customer_id IN (SELECT DISTINCT customer_id
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'); # 10826
SELECT COUNT(DISTINCT customer_id)
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'; # 16414
SELECT ROUND(11174/16414*100,2); # 68퍼센트..?
SELECT ROUND(10826/16414*100,2); # 65퍼센트라고 나는 생각..ARPU: Average Revenue Per User- 매출 / 중복을 제외한 순수 Active User 수
- 모든 사용자를 대상으로 하기 때문에, 프로덕트가 평균적으로 어느 정도의 현금 유도를 해내는지 판단하는 지표로 사용됨
- 현재 사용자 트래픽으로 목표 매출을 얼마정도 달성할 수 있는지 예측
ARPPU: Average Revenue Per Paying User. 객단가(Average Order Value;AOV )라고도 함- 매출 / 중복을 제외한 순수 유료 사용자 수 = 유료 사용자 1인당 평균 금액
- 분모가 작아지므로 당연히
ARPU보다 값이 클 수 밖에 없음 - 사용자가 허용할 수 있는 최대 가격선을 파악하는 데 도움
- 서비스의 금액을 높인다면 ARPPU는 올라가지만, 금액이 향상된 만큼 지불할 의사가 없는 사용자들은 서비스를 이탈할 가능성이 높아짐
Average Check- 1회 당 평균 금액
- 매출(Revenue) / 거래 횟수(Transaction)
- ARPPU와 자주 헷갈리는 개념. ARPPU는 분모가 유료 사용자 수이고, Average Check는 거래 횟수임에 주의
- 사용자가 구매를 반복적으로 하면 할수록 ARPPU와 Average Check의 차이는 커진다.
ARPDAU: Average Revenue Per Daily Active User.- 일일 활성 유저 1인당 평균 매출액
- 특정일에 앱을 사용한 유저들에 대한 비율을 보여준다
[Ad Tech 101] 앱의 수익 측정 공식: ARPU vs ARPPU vs ARPDAU ㅣ 네이티브엑스
# 방법 1
SELECT AVG(revenue) # 1884750.8770
FROM (
SELECT customer_id,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY customer_id) foo;
# 방법 2
SELECT SUM(price)/COUNT(DISTINCT customer_id) AS revenue # 1884750.8770
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01';고과금 유저를 조회하는 문제LIMIT문에서OFFSET사용
SELECT customer_id, SUM(price), RANK() OVER (ORDER BY SUM(price) DESC) AS ranking
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY customer_id
ORDER BY SUM(price) DESC
LIMIT 6 OFFSET 9;
# OFFSET : 지정한 수만큼 잘라먹고 그 뒤로 보여주기 LIMIT 9,6과 같은 결과💵 2. 날짜, 시간별 분석
- 간단한 날짜 함수
SELECT NOW();
SELECT CURRENT_DATE();
SELECT EXTRACT(MONTH FROM '2021-01-01'); # 원하는 날짜 추출
SELECT DAY('2021-01-01');
SELECT DATE_ADD('2021-01-01', INTERVAL 7 DAY); # INTERVAL n DAY : 원하는 만큼 날짜 더하고 빼고
SELECT DATE_SUB('2017-06-15', INTERVAL 7 DAY);
SELECT DATEDIFF("2017-06-25", "2017-06-15 09:47:45"); # 10. 시간은 무시되는 듯
SELECT TIMEDIFF("2021-01-25 12:10:00", "2021-01-25 10:10:00");
SELECT DATE_FORMAT(NOW(), "%Y-%m-%d %p");- SELECT 절에 집계함수를 쓸 때 : SELECT 절의 집계함수를 제외한 모든 COLUMN은 GROUP BY절에 명시해줘야 한다!
DAU: Daily Active User; 일일 활성 유저- 날짜/시간의 포맷팅, 연산은 늘 시간의 변화에 주의해야 한다!
- 실무 엔지니어들이 데이터를 어떻게 세팅해주냐에 따라 달라질 수도 있고, 짐작컨대 KST 한국표준 시간대를 사용중인데, formatting과정에서 UTC로 변환이 되어 KST가 9시간 빠르니까 -9hour를 해줘야 하는 것 같음
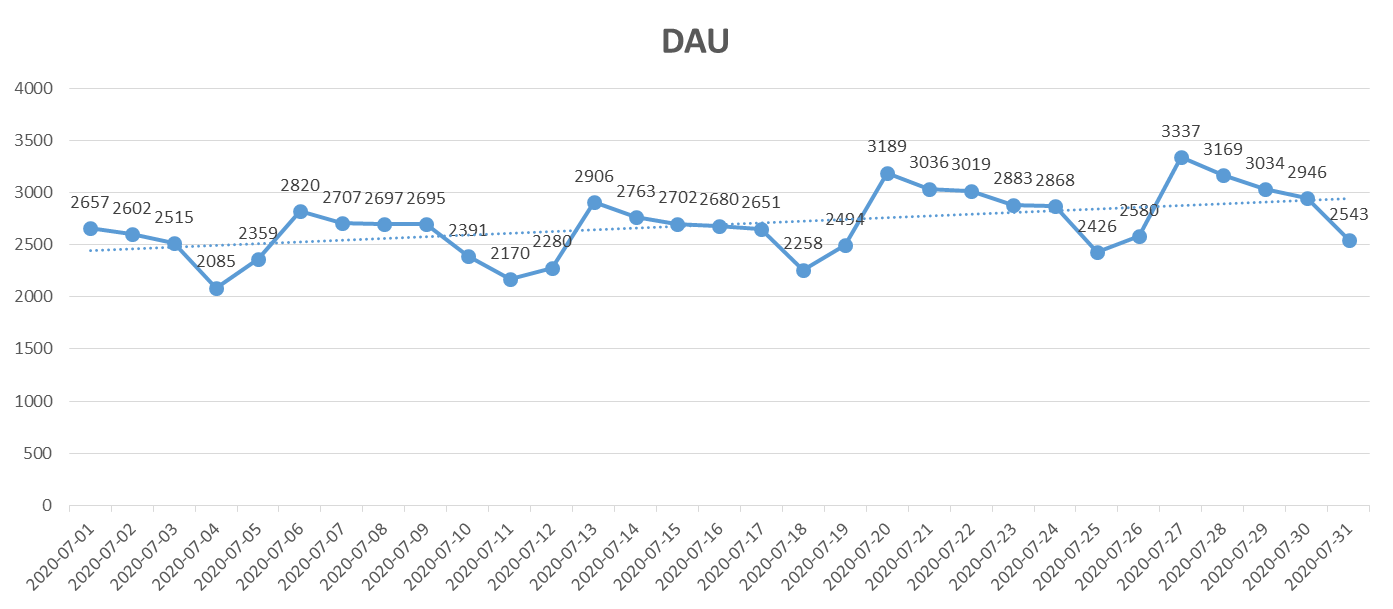
# 단계1 : 결과에 이상하게 8월 1일이 들어가있다...
-- > 시간대의 포맷팅과 연산에서는 시간의 변화에 늘 주의해야 한다!!!
SELECT date_format(visited_at, '%Y-%m-%d') AS date_at,
COUNT(distinct customer_id)
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'
GROUP BY date_at;
# 단계2 : 시간 변화 확인 작업 -> 보면 date_format() 쓰니까 9시간씩 더해졌음 -> 더해진 만큼 빼줘야 맞아짐
# 정확한 원인은 알수 없음 : 실무할 때 엔지니어들이 어떻게 세팅을 해주냐에 따라 달라질 수 있고,
# 짐작컨대 KST 한국표준 시간대를 사용중인데, formatting과정에서 UTC로 변환이 되어 KST가 9시간 빠르니까 -9hour를 해줘야 하는 것 같음
SELECT *, date_format(visited_at, '%Y-%m-%d %T') AS date_at, date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%d %T')
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01';
# 단계3 : 제대로 포맷팅된 시간으로 다시 결과 내기
SELECT date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%d') AS date_at,
COUNT(distinct customer_id)
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'
GROUP BY date_at
ORDER BY date_at;
# 단계4: 7월의 평균 DAU와 추세 확인 -> Excel로 Export해서 그래프 확인
# 추세: 전반적으로는 미세하게 증가하는 추세, 요일을 타는 것 같음
SELECT AVG(au)
FROM (
SELECT date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%d') AS date_at,
COUNT(distinct customer_id) AS au
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'
GROUP BY date_at
ORDER BY date_at) foo; # 2692.3226WAU: Weekly Active User; 주별 활성 유저- 뽑을 때 주의할 점 : 7일을 온전히 포함하는 주만 비교가능
%U: 1년 52주 중에 몇번째 주인지 나타내는 포매팅(일요일부터 한주 시작)
# 단계1 : %U : 1년 52주 중에 몇번째 주인지 나타내는 포매팅(일요일부터 한주 시작)
# 그런데 5주나 나오는 것을 보아, 앞 뒤로 뽑힌 주는 온전히 7일을 포함하지 않을 것 같다
-- > 가장 간단한 확인 법 : 컴퓨터 달력 보기(7.5~7.25)
SELECT date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%U') AS date_at,
COUNT(distinct customer_id) AS au
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'
GROUP BY date_at
ORDER BY date_at;
# 단계2 : 기간 조정 후 다시 뽑기
# 추세 : 증가하는 추세
SELECT date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%U') AS date_at,
COUNT(distinct customer_id) AS au
FROM tbl_visit
WHERE visited_at >= '2020-07-05'
AND visited_at < '2020-07-26'
GROUP BY date_at
ORDER BY date_at;
# 단계3 : 평균 WAU
SELECT AVG(au) AS wau
FROM(
SELECT date_format(visited_at - INTERVAL 9 HOUR, '%Y-%m-%U') AS date_at,
COUNT(distinct customer_id) AS au
FROM tbl_visit
WHERE visited_at >= '2020-07-05'
AND visited_at < '2020-07-26'
GROUP BY date_at
ORDER BY date_at
) foo; # 8717.6667- Daily~ Weekly~ 로 뭔가를 뽑을 때는 분모가 해당 날짜로 GROUP BY되어야 하므로, 꼭 서브쿼리를 활용하도록 한다
- 그렇지 않으면, Transaction이 분모에 들어가는 대참사가 벌어짐

SELECT DATE_FORMAT(purchased_at- INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
SUM(price) AS Revenue_daily
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at
ORDER BY date_at;
/* 추세 : DAU의 패턴과 크게 다르지 않음. 객단가가 높아졌다고 보긴 어렵고,
단순히 AU가 증가해서 그런것 아닐까? */
-- 평균 Daily Revenue
SELECT AVG(Revenue_daily) AS avg_Revenue_daily
FROM (SELECT DATE_FORMAT(purchased_at- INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
SUM(price) AS Revenue_daily
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at
ORDER BY date_at) foo;
-- 679,361,493.5484 원
💡 Q9 : 2020년 7월의 평균 Weekly Revenue를 구해주세요
- Daily~ Weekly~ 로 뭔가를 뽑을 때는 분모가 해당 날짜로 GROUP BY되어야 하므로, 꼭 서브쿼리를 활용하도록 한다
SELECT DATE_FORMAT(purchased_at- INTERVAL 9 HOUR,'%Y-%m-%U') AS date_at,
SUM(price) AS Revenue_weekly
FROM tbl_purchase
WHERE purchased_at >= '2020-07-05'
AND purchased_at < '2020-07-26'
GROUP BY date_at
ORDER BY date_at;
# 평균 Weekly Revenue
SELECT AVG(Revenue_weekly) AS avg_Revenue_weekly
FROM (SELECT DATE_FORMAT(purchased_at- INTERVAL 9 HOUR,'%Y-%m-%U') AS date_at,
SUM(price) AS Revenue_weekly
FROM tbl_purchase
WHERE purchased_at >= '2020-07-05'
AND purchased_at < '2020-07-26'
GROUP BY date_at
ORDER BY date_at) foo;
# 4,752,833,266.6667 원- 요일별 평균 Revenue → 분모에 뭐가 들어가야 맞는지를 생각해보자
- 단계적으로 먼저 서브쿼리에서 일별로 GROUP BY 해서 transaction을 일별로 모아준다
- 다음 OUTER QUERY에서 일별 서브쿼리를 요일로 GROUP BY 해서 요일별 평균을 계산
- 해석 : 주말로 진입하는 금요일부터 토, 일의 매출이 낮고, 평일의 매출이 높다
| day_name | day_order | revenue_weekname |
|---|---|---|
| Sunday | 0 | 588118425 |
| Monday | 1 | 792136675 |
| Tuesday | 2 | 754844275 |
| Wednesday | 3 | 689290280 |
| Thursday | 4 | 714763100 |
| Friday | 5 | 661051300 |
| Saturday | 6 | 548571350 |
# 실수 : 바로 요일별 avg를 구하면 -> 각 요일의 결제당 평균 금액 (한마디로 분모가 잘못됨)
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,"%W") AS date_at,
AVG(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at;
/* 해결 : 먼저 0701~0731까지 daily 총 daily revenue를 구해서
-> 이걸 서브쿼리로 받아서 요일별 AVG(revenue)를 구해야 요일별 평균 avg가 나옴*/
SELECT DATE_FORMAT(date_at, "%W") as day_name,
DATE_FORMAT(date_at, "%w") as day_order, # 0 = Sunday
AVG(revenue) AS revenue_weekname
FROM (
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
SUM(price) AS revenue
FROM tbl_purchase
****WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at) foo
GROUP BY day_order, day_name
ORDER BY day_order;
# 매출순으로 값 보기
SELECT DATE_FORMAT(date_at, "%W") as day_name,
AVG(revenue) AS revenue_weekname
FROM (
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at) foo
GROUP BY day_name
ORDER BY revenue_weekname DESC;
# 해석 : 주말로 진입하는 금요일부터 토, 일의 매출이 낮고, 평일의 매출이 높다- 시간대별 평균 Revenue → 분모에 뭐가 들어가야 맞는지를 생각해보자
- 단계적으로 먼저 서브쿼리에서 일별, 시간대로 2개 GROUP BY 해서 transaction을 일별로 모아준다
- 다음 OUTER QUERY에서 일별 서브쿼리를 시간대로 GROUP BY 해서 시간대별 평균을 계산
%H: 24시 시간 포맷팅
| hour_at | revenue_hour |
|---|---|
| 18 | 38557135 |
| 16 | 38474416 |
| 19 | 38213132 |
| 15 | 37360761 |
| - | - |
| 4 | 14395461 |
| 5 | 9835809.7 |
| 7 | 9714574.2 |
| 6 | 8767238.7 |
- 해석 : 오후 퇴근 시간대에 매출이 가장 높고, 아침 출근(새벽)시간대에 매출이 가장 낮다
# 1단계 : 이역시 먼저 서브쿼리를 작성해보기
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%H') AS hour_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at, hour_at;
# 2단계 : 서브쿼리를 포함해 시간대별 평균 Revenue를 구하는 쿼리 짜보기
SELECT hour_at,
AVG(revenue) AS revenue_hour
FROM (SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%Y-%m-%d') AS date_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR,'%H') AS hour_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at, hour_at) foo
GROUP BY hour_at
ORDER BY revenue_hour DESC;
# 해석 : 오후 퇴근 시간대에 매출이 가장 높고, 아침 출근(새벽)시간대에 매출이 가장 낮다- 요일 및 시간대별 평균 Revenue → 분모에 뭐가 들어가야 맞는지를 생각해보자
- 단계적으로 먼저 서브쿼리에서 일별, 요일별, 시간대로 3개 GROUP BY 해서 transaction을 일별로 모아준다(일별이 들어가야 2020년 7월의 평균값을 찾는 의미가 생김)
- 다음 OUTER QUERY에서 일별 서브쿼리를 요일 및 시간대로 GROUP BY 해서 요일,시간대별 평균을 계산
| dayofweek_at | hour_at | AVG(revenue) |
|---|---|---|
| Monday | 18 | 46862325 |
| Monday | 21 | 46132850 |
| Monday | 17 | 45574800 |
| Monday | 19 | 45555850 |
| Monday | 16 | 45445000 |
| Tuesday | 19 | 45061750 |
| - | - | - |
| Tuesday | 6 | 8517475 |
| Sunday | 6 | 8293625 |
| Saturday | 5 | 8047150 |
| Saturday | 6 | 7456250 |
- 해석 : 월요일 퇴근시간대가 매출이 가장 높고, 주말 아침(새벽)에 매출이 가장 떨어진다
# 앞의 두문제를 합쳐서 가장 세분화된 분석 -> 시작은 daily base를 만들기
# base
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%Y-%m-%d') AS date_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%W') AS dayofweek_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%H') AS hour_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at, dayofweek_at, hour_at;
# 서브쿼리를 포함해 요일별, 시간대별 평균 Revenue를 구하는 쿼리 짜보기
SELECT dayofweek_at, hour_at,
AVG(revenue)
FROM(SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%Y-%m-%d') AS date_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%W') AS dayofweek_at,
DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, '%H') AS hour_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at, dayofweek_at, hour_at) foo
GROUP BY dayofweek_at, hour_at
ORDER BY AVG(revenue) DESC;
# 해석 : 월요일 퇴근시간대가 매출이 가장 높고, 주말 아침(새벽)에 매출이 가장 떨어진다- 요일 및 시간대별 평균 Revenue → 분모에 뭐가 들어가야 맞는지를 생각해보자
- 단계적으로 먼저 서브쿼리에서 일별, 요일별, 시간대로 3개 GROUP BY 해서 transaction을 일별로 모아준다(일별이 들어가야 2020년 7월의 평균값을 찾는 의미가 생김)
- 다음 OUTER QUERY에서 일별 서브쿼리를 요일 및 시간대로 GROUP BY 해서 요일, 시간대별 평균을 계산
| dayofweek_at | hour_at | AVG(active_user) |
|---|---|---|
| Monday | 17 | 259 |
| Monday | 15 | 254.25 |
| Tuesday | 17 | 252 |
| Monday | 14 | 244.25 |
| Monday | 16 | 241.75 |
| Monday | 18 | 235 |
| Monday | 22 | 233 |
| Monday | 12 | 232.5 |
| Monday | 13 | 231.75 |
| - | - | - |
| Friday | 3 | 33.6 |
| Saturday | 3 | 32.75 |
| Wednesday | 3 | 32.4 |
| Thursday | 4 | 31.6 |
| Tuesday | 4 | 30.5 |
| Friday | 4 | 29.4 |
| Saturday | 4 | 27.75 |
| Sunday | 4 | 26.75 |
| Wednesday | 4 | 25.6 |
- 해석 : 월요일 퇴근 시간대 AU가 많고, 월요일 오후에 AU가 전반적으로 높다. 새벽 시간대(01~05)에 요일과 상관없이 전반적으로 AU가 적다
- AU와 Revenue를 비교해서 경향이 비슷하다면 특정 객단가가 높다기보다는, AU가 많아서 Revenue가 많이 나왔다는 가설 세울 수 있음
SELECT dayofweek_at, hour_at,
AVG(active_user)
FROM(SELECT DATE_FORMAT(visited_at - INTERVAL 9 HOUR, '%Y-%m-%d') AS date_at,
DATE_FORMAT(visited_at - INTERVAL 9 HOUR, '%W') AS dayofweek_at,
DATE_FORMAT(visited_at - INTERVAL 9 HOUR, '%H') AS hour_at,
COUNT(DISTINCT customer_id) AS active_user
FROM tbl_visit
WHERE visited_at >= '2020-07-01'
AND visited_at < '2020-08-01'
GROUP BY date_at, dayofweek_at, hour_at) foo
GROUP BY dayofweek_at, hour_at
ORDER BY AVG(active_user) DESC;
/*해석 : 월요일 퇴근 시간대 AU가 많고, 월요일 오후에 AU가 전반적으로 높다.
새벽 시간대(01~05)에 요일과 상관없이 전반적으로 AU가 적다*/💵 3. 유저 세그먼트별 분석
- dirty한 데이터로 인해
IS NULL이 제대로 안먹힐 때 ->LENGTH()사용 - 계속 오류났던거 : CASE문으로 똑같은 COLUMN명으로 덮을 때는, 순서(1,2)로 해줘야 제대로 먹음(컬럼명 gender, age로 해보면 계속 이상하게 나옴)
| gender | age | COUNT(*) |
|---|---|---|
| F | 21-25세 | 3207 |
| F | 26-30세 | 2687 |
| M | 21-25세 | 1979 |
| M | 26-30세 | 1567 |
| - | - | - |
| Others | 16-20세 | 9 |
| Others | 31-35세 | 8 |
| Others | 15세 이하 | 6 |
| Others | 36-40세 | 6 |
- 해석 : 여성 21-30세가 가장 많고, 그 다음은 남성 21-30세
SELECT * FROM tbl_customer LIMIT 10;
SELECT DISTINCT gender FROM tbl_customer; # F, M, '', Others
SELECT DISTINCT age FROM tbl_customer ORDER BY age; # 12 ~ 57
# 성별 : dirty한 데이터로 인해 IS NULL이 제대로 안먹힐 때 -> LENGTH() 사용
SELECT CASE WHEN LENGTH(gender) < 1 THEN 'Others'
ELSE gender END AS gender,
CASE WHEN age <=15 THEN '15세 이하'
WHEN age <=20 THEN '16-20세'
WHEN age <=25 THEN '21-25세'
WHEN age <=30 THEN '26-30세'
WHEN age <=35 THEN '31-35세'
WHEN age <=40 THEN '36-40세'
WHEN age <=45 THEN '41-45세'
WHEN age >=46 THEN '46세 이상'
END AS age,
COUNT(*)
FROM tbl_customer
GROUP BY 1, 2
ORDER BY COUNT(*) DESC; # GROUP BY절은 SELECT 집계함수 이외의 모든 컬럼 명시
# 해석 : 여성 21-30세가 가장 많고, 그 다음은 남성 21-30세- 문제의도 : 쿼리로 리포팅 자동화를 해야할 때가 있음 ->
CONCAT()함수 사용시 효율적으로 처리 가능 - 전체 분포를 구할 때는 분모에
스칼라 서브쿼리활용
| segment | percentage(%) |
|---|---|
| 여성(21-25세) | 22.54 |
| 여성(26-30세) | 18.89 |
| 남성(21-25세) | 13.91 |
| 남성(26-30세) | 11.02 |
| - | - |
| 기타(16-20세) | 0.06 |
| 기타(31-35세) | 0.06 |
| 기타(15세 이하) | 0.04 |
| 기타(36-40세) | 0.04 |
# 단계1 : 성별과 연령을 하나의 컬럼으로 통합
SELECT **CONCAT**(CASE WHEN LENGTH(gender) < 1 THEN '기타'
WHEN gender = 'Others' THEN '기타'
WHEN gender = 'F' THEN '여성'
WHEN gender = 'M' THEN '남성'
END,
"(",
CASE WHEN age <=15 THEN '15세 이하'
WHEN age <=20 THEN '16-20세'
WHEN age <=25 THEN '21-25세'
WHEN age <=30 THEN '26-30세'
WHEN age <=35 THEN '31-35세'
WHEN age <=40 THEN '36-40세'
WHEN age <=45 THEN '41-45세'
WHEN age >=46 THEN '46세 이상'
END,
")") AS segment,
COUNT(*)
FROM tbl_customer
GROUP BY 1;
# 단계2 : 전체에서 차지하는 분포 확인(높은 순으로)
SELECT CONCAT(CASE WHEN LENGTH(gender) < 1 THEN '기타'
WHEN gender = 'Others' THEN '기타'
WHEN gender = 'F' THEN '여성'
WHEN gender = 'M' THEN '남성'
END,
"(",
CASE WHEN age <=15 THEN '15세 이하'
WHEN age <=20 THEN '16-20세'
WHEN age <=25 THEN '21-25세'
WHEN age <=30 THEN '26-30세'
WHEN age <=35 THEN '31-35세'
WHEN age <=40 THEN '36-40세'
WHEN age <=45 THEN '41-45세'
WHEN age >=46 THEN '46세 이상'
END,
")") AS segment,
ROUND(COUNT(*)/(SELECT COUNT(*) FROM tbl_customer)*100,2) AS 'percentage(%)'
FROM tbl_customer
GROUP BY 1
ORDER BY 2 DESC;- 인적 정보와 Revenue 정보는 서로 다른 테이블에 존재 → JOIN 사용
SELECT CASE WHEN gender = 'M' THEN '남성'
WHEN gender = 'F' THEN '여성'
ELSE '기타' END AS gender,
COUNT(*) AS cnt,
SUM(price) AS revenue
FROM tbl_purchase P
LEFT JOIN tbl_customer C
ON P.customer_id = C.customer_id
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY 1;| gender | age | cnt | revenue |
|---|---|---|---|
| 여성 | 21-25세 | 9233 | 4.75E+09 |
| 여성 | 26-30세 | 7548 | 3.83E+09 |
| 남성 | 21-25세 | 5879 | 3E+09 |
| 남성 | 26-30세 | 4640 | 2.34E+09 |
| - | - | - | - |
| 기타 | 16-20세 | 47 | 20719600 |
| 기타 | 15세 이하 | 33 | 17839900 |
| 기타 | 31-35세 | 25 | 12983700 |
| 기타 | 21-25세 | 14 | 9412000 |
| 기타 | 36-40세 | 15 | 8998800 |
- 해석 : 객단가가 높은게 아니라, 단순히 유저수가 많아서 총 매출이 높은 그룹임(여성,남성 20대)
SELECT CASE WHEN gender = 'M' THEN '남성'
WHEN gender = 'F' THEN '여성'
ELSE '기타' END AS gender,
CASE WHEN age <=15 THEN '15세 이하'
WHEN age <=20 THEN '16-20세'
WHEN age <=25 THEN '21-25세'
WHEN age <=30 THEN '26-30세'
WHEN age <=35 THEN '31-35세'
WHEN age <=40 THEN '36-40세'
WHEN age <=45 THEN '41-45세'
WHEN age >=46 THEN '46세 이상'
END AS age,
COUNT(*) AS cnt,
SUM(price) AS revenue
FROM tbl_purchase P
LEFT JOIN tbl_customer C
ON P.customer_id = C.customer_id
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY 1,2
ORDER BY 4 DESC; # 3,4 desc 각각 해보기
# 해석 : 객단가가 높은게 아니라, 단순히 유저수가 많아서 총 매출이 높은 그룹임(여성,남성 20대)💵 4. 매출 관련 추가 분석
WITH문- 여러번 사용되어야 하는 서브쿼리를 아예 테이블로 정의하는 방법
- WITH 절은 서브쿼리를 정의하는 용도로 사용되며, 단독으로 실행되지 않습니다
- WITH 절 이후에 메인 쿼리에서 정의한 서브쿼리를 참조하여 사용해야 합니다
- WITH 절은 메인 쿼리의 실행에 영향을 미치는 서브쿼리를 먼저 정의하고, 이후에 메인 쿼리에서 이를 활용하는 데 사용됩니다.
- 주의 : WITH 절에서는 각 컬럼에
별칭(alias)을 지정해 주어야 함
- SELCET문의 별칭(Alias)
- Q. 쿼리문의 실행순서에 따르면 GROUP BY 이후 SELECT 문이 실행되는게 맞는데, 어떻게 GROUP BY에서 SELECT문의 alias를 인식할 수 있는가?
- A. SQL의 논리적 처리순서와는 조금 다른 부분이고, 다음의 경우에 사용된다.
- 연산의 결과에 이름을 붙이기
GROUP BY,HAVING,ORDER BY절에서 사용하기
- 주의 : 다음과 같이 사용은 불가능하다
-- 옳은 사용
SELECT revenue * 0.1 AS tax, revenue + (revenue * 0.1) AS total
FROM sales;
-- 잘못된 사용(ERROR)
SELECT revenue * 0.1 AS tax, revenue +tax AS total
FROM sales;
- 윈도우 함수(Windows Function)
- 윈도우 함수(Windows Function)는 행 집합 내에서 특정 윈도우(범위)에 대한 계산을 수행하는 함수입니다.
- 이 함수들은 일반적으로 OVER 절을 사용하여 윈도우를 정의하며, 윈도우는 정렬된 순서에 따라 현재 행을 중심으로 어떤 범위의 행을 나타냅니다
- 전날의 revenue를 가져오는 함수 ->
LAG()함수(윈도우함수중 하나)
| date_at | revenue | diff_revenue | chg_revenue(%) |
|---|---|---|---|
| 2020-07-01 | 565923600 | ||
| 2020-07-02 | 685876200 | 119952600 | 21.2 |
| 2020-07-03 | 646678600 | -39197600 | -5.71 |
| 2020-07-04 | 479846400 | -166832200 | -25.8 |
| - | - | - | - |
| 2020-07-29 | 749529200 | -57437400 | -7.12 |
| 2020-07-30 | 712723700 | -36805500 | -4.91 |
| 2020-07-31 | 657446800 | -55276900 | -7.76 |
# 단계 1 : 여러번 사용되어야 하는 서브쿼리를 아예 테이블로 정의하는 방법 : WITH 문
WITH tbl_revenue AS (
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") AS date_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at
)
SELECT * FROM tbl_revenue;
# 단계 2 : 전일의 revenue를 가져오는 함수 -> lag함수(윈도우함수중 하나)
WITH tbl_revenue AS (
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") AS date_at,
SUM(price) AS revenue
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at
)
SELECT *,
revenue - LAG(revenue) OVER (ORDER BY date_at) AS diff_revenue,
ROUND((revenue - LAG(revenue) OVER (ORDER BY date_at))/LAG(revenue) OVER (ORDER BY date_at)*100,2) AS 'chg_revenue(%)'
FROM tbl_revenue;- 윈도우 함수의
PARTITION BY옵션 - 윈도우를 나눌 기준 열을 지정(옵션)
-- RANK() OVER (ORDER BY price DESC)
-- 7월 2일 A 4000 1
-- 7월 1일 A 3000 2
-- 7월 1일 A 2000 3
-- 7월 1일 B 2000 3
-- 7월 1일 A 1000 5
-- 7월 1일 B 1000 5
-- RANK() OVER (PARTITION BY c1,c2 ORDER BY price DESC)
-- 7월 1일 A 3000 1
-- 7월 1일 A 2000 2
-- 7월 1일 A 1000 3
-- 7월 1일 B 2000 1
-- 7월 1일 B 1000 2
-- 7월 2일 A 4000 1
- 구매 금액을 기준으로 랭크를 매길 것이기 때문에 ,
RANK()함수 말고DENSE_RANK()로
# 구매금액을 기준으로 하니까 RANK()말고 DENSE_RANK()로!
-- (ex. 1000, 1000, 1000, 500, 300일 때 300까지 전부 포함해야 하니까)
SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") AS date_at,
customer_id,
SUM(price) AS revenue,
DENSE_RANK() OVER (PARTITION BY DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") ORDER BY SUM(price) DESC) AS ranking
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at,customer_id
ORDER BY date_at, SUM(price) DESC;
# 서브쿼리화 해서 결과 내기
SELECT *
FROM (SELECT DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") AS date_at,
customer_id,
SUM(price) AS revenue,
DENSE_RANK() OVER (PARTITION BY DATE_FORMAT(purchased_at - INTERVAL 9 HOUR, "%Y-%m-%d") ORDER BY SUM(price) DESC) AS ranking
FROM tbl_purchase
WHERE purchased_at >= '2020-07-01'
AND purchased_at < '2020-08-01'
GROUP BY date_at,customer_id) foo
WHERE ranking < 4
ORDER BY date_at,ranking;💵 5. 프로덕트 분석 심화
Paying Conversion(결제 전환율)- 비즈니스가 제품 또는 서비스를 이용하는 고객들 중에서 얼마나 많은 비율이 실제로 결제를 완료하는지를 측정하는 데 사용됨
- 문제 풀이
- 단계 1 : JOIN 방법 : 결제를 하지 않은 정보도 있어야 하므로 tbl_customer 기준으로 LEFT JOIN
- 단계 2 : 조건에 걸러진 NULL값을 이용하기 위해 ( RIGHT KEY / LEFT KEY ) 비율 계산
- 포인트 : 지금까지는 조건이 갈 수 있는 절이 WHERE, HAVING 두 개 뿐이라 생각했는데, 아니다!
- LEFT, RIGHT, OUTER 조인과 같은 특수 조인에서는 ON 절에도 IS NULL 조건을 활용하기 위해 조건을 걸수 있다는 것!
- 아래 문제에서 first_purchased값이 NULL로 나오는 이유(아래의 조건에 해당되면 조인으로 붙는 테이블의 키 포함 모든 값이 NULL로 붙게 됨)
- purchased table에 구매이력이 없어서 LEFT JOIN에서 NULL이 된 경우
- 결제는 했으나, ON에서 걸어준 하루결제조건에서 걸린 경우
-- 신규유저 Paying Conversion(중요한 비즈니스 지표)
-- 문제를 풀기 위해 필요한 것 : 신규유저 가입일, 최초 구매일
# 단계 1 : JOIN 방법 : 결제를 하지 않은 정보도 있어야 하므로 tbl_customer 기준으로 LEFT JOIN
SELECT C.customer_id,
C.created_at,
P.customer_id AS paying_user,
P.first_purchased,
-- C.created_at + INTERVAL 24 HOUR AS test_time,
TIME_TO_SEC(TIMEDIFF(P.first_purchased, C.created_at))/3600 AS diff_hour
FROM tbl_customer C
LEFT JOIN (SELECT customer_id, MIN(purchased_at) AS first_purchased
FROM tbl_purchase
GROUP BY customer_id) P
ON C.customer_id = P.customer_id
AND P.first_purchased < C.created_at + INTERVAL 15 HOUR # 하루 안에 결제로 넘어가는 조건(24-9HOUR)
WHERE created_at >= '2020-07-01'
AND created_at < '2020-08-01';
# first_purchased값이 NULL로 나오는 이유
-- 1. purchased table에 구매이력이 없어서 LEFT JOIN에서 NULL이 된 경우
-- 2. 결제는 했으나, ON에서 걸어준 하루결제조건에서 걸린 경우
# 단계 2 : 위에서 만든 테이블을 서브쿼리로 결과 도출
WITH rt_tbl AS (
SELECT C.customer_id,
-- C.created_at,
P.customer_id AS paying_user,
-- P.first_purchased,
TIME_TO_SEC(TIMEDIFF(P.first_purchased, C.created_at))/3600 AS diff_hour
FROM tbl_customer C
LEFT JOIN (SELECT customer_id, MIN(purchased_at) AS first_purchased
FROM tbl_purchase
GROUP BY customer_id) P
ON C.customer_id = P.customer_id
AND P.first_purchased < C.created_at + INTERVAL 15 HOUR
WHERE created_at >= '2020-07-01'
AND created_at < '2020-08-01')
# 결제 전환율
SELECT ROUND(COUNT(paying_user)/COUNT(customer_id)*100,2) AS answer # COUNT()함수에서 알아서 NULL값 제외
FROM rt_tbl # paying conversion : 20.66%
UNION ALL
# 결제까지 보통 몇 분 정도가 소요되는 지
SELECT ROUND(AVG(diff_hour),2)
FROM rt_tbl; # 평균 소요시간 : 10.18 시간
# 해석 : 20퍼센트 가량의 전환률에 비해 오랜 시간이 걸리는 것 같다 -> 이 시간을 줄여서 결제 전환율을 더 높이는 방법이 필요Retention: 시간이 지날수록 얼마나 많은 유저가 다시 서비스로 돌아오는가- retention은 그로스(growth)에 있어서 핵심적인 요소
- Amplitude가 5억 개의 모바일 기기를 분석한 결과, 평균적으로 80%의 신규 유저는 앱 다운로드 3일 후부터 더 이상 해당 앱을 사용하지 않는다는 결과
- 리텐션은 기업(그리고 투자자들)이 중요하게 여기는 활성 유저 수, 인게이지먼트, LTV(고객 생애 가치), 페이백 기간 등 모든 주요 핵심 지표에 영향을 미침
- N-day Retention : n=1,2,3,4,,,30,,
- 7월 1일의 Day7 Retention : 일주일 뒤인 7월 8일에 몇 명이 남아있는지 그 비율을 따져보는 것
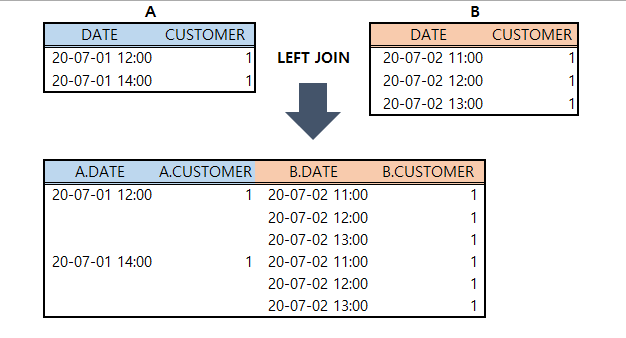
- 포인트 : SELF JOIN을 활용해서 푸는 문제! + DISTINCT 의 활용!
- 이 문제 또한 A LEFT JOIN B으로 A테이블을 당일, B테이블을 하루 뒤의 접속을 기준으로 ON에 조건을 주면, 1DAY retention 이 유지되는 유저만 NULL이 아닌 값으로 붙을 것
- LEFT JOIN시 하루에 여러 번 접속한 유저는 여러 개의 row로 JOIN이 되어버리는 문제 발생 → COUNT(DISTINCT customer_id) 사용으로 중복값을 간단히 제거 가능
성장을 위한 필수 지표, 유저 리텐션 향상 전략 - Liftoff
| d_date | active_user | retained_user | retention |
|---|---|---|---|
| 2020-07-01 | 2657 | 1008 | 0.3794 |
| 2020-07-02 | 2602 | 968 | 0.372 |
| 2020-07-03 | 2515 | 824 | 0.3276 |
| 2020-07-04 | 2085 | 757 | 0.3631 |
| - | - | - | - |
| 2020-07-30 | 2946 | 1032 | 0.3503 |
| 2020-07-31 | 2543 | 926 | 0.3641 |
-- retention은 고객을 유지시키는 전략에 굉장히 중요한 지표로 판단되고 있음
SELECT * FROM tbl_visit LIMIT 10;
# 이 문제는 SELF JOIN을 활용해 푸는 문제!
-- 아래에서 A는 당일, B는 다음날
SELECT DATE_FORMAT(A.visited_at - INTERVAL 9 HOUR,'%y-%m-%d') AS d_date,
COUNT(DISTINCT A.customer_id) AS active_user, # 여기에 써준 DISTINCT 가 하루에 여러번 접속한 유저도 해결해줌..
COUNT(DISTINCT B.customer_id) AS retained_user,
COUNT(DISTINCT B.customer_id)/COUNT(DISTINCT A.customer_id) AS retention
FROM tbl_visit A
LEFT JOIN tbl_visit B
ON A.customer_id = B.customer_id
AND DATE_FORMAT(A.visited_at - INTERVAL 9 HOUR, '%y-%m-%d') = DATE_FORMAT(B.visited_at - INTERVAL 9 HOUR - INTERVAL 1 DAY, '%y-%m-%d')
WHERE A.visited_at >= '2020-07-01'
AND A.visited_at < '2020-08-01'
GROUP BY d_date;
# ON 조건에서 만족하지 못하는 retained_user 는 NULL 값을 갖게 될 것이다
# 하루에 여러번 접속하는 사람은 어떻게 처리해야 하는가?
-- > 위의 문제에서는 이 중복을 전부 포함해서 계산했음(이라고 생각했는데, OUTER QUERY에서 d_date로 그룹핑하면서 집계함수에서 DISTINCT 넣어주니 전부 해결됨 와우)
SELECT *
FROM tbl_visit
WHERE customer_id = '47084';
SELECT DATE_FORMAT(A.visited_at - INTERVAL 9 HOUR,'%y-%m-%d') AS d_date,
COUNT(A.customer_id) AS active_user,
COUNT(B.customer_id) AS retained_user,
COUNT(B.customer_id)/COUNT(A.customer_id) AS retention
FROM (SELECT DATE_FORMAT(visited_at - INTERVAL 9 HOUR, '%y-%m-%d'), customer_id, MAX(visited_at) AS visited_at FROM tbl_visit GROUP BY 1,2) A
LEFT JOIN (SELECT DATE_FORMAT(visited_at - INTERVAL 9 HOUR, '%y-%m-%d'), customer_id, MIN(visited_at) AS visited_at FROM tbl_visit GROUP BY 1,2) B
ON A.customer_id = B.customer_id
AND DATE_FORMAT(A.visited_at - INTERVAL 9 HOUR, '%y-%m-%d') = DATE_FORMAT(B.visited_at - INTERVAL 9 HOUR - INTERVAL 1 DAY, '%y-%m-%d')
WHERE A.visited_at >= '2020-07-01'
AND A.visited_at < '2020-08-01'
GROUP BY d_date;User (Service) Age: 유저의 서비스 나이를 의미- 이 지표로 진성 유저의 점착도, 우리 프로덕트의 수명 주기가 어느 단계정도에 있는지 등을 알 수 있음
- 문제를 풀기 위해 필요한 것 : tbl_visit 일자별로 고객의 last_visit 체크, tbl_customer created_at 체크 -> 둘의 차이 = User age
- JOIN 방법 : 상관 없을 것 같긴한데, 빼주는 파이가 담긴 테이블이 기준이 되는 게 맞는 것 같음
| d_date | segment | all_users | users | percent(%) |
|---|---|---|---|---|
| 2020-07-01 | 1_2년 이상 | 2657 | 537 | 20.21 |
| 2020-07-01 | 2_1년 이상 | 2657 | 596 | 22.43 |
| 2020-07-01 | 3_6개월 이상 | 2657 | 389 | 14.64 |
| 2020-07-01 | 4_3개월 이상 | 2657 | 270 | 10.16 |
| 2020-07-01 | 5_1개월 이상 | 2657 | 268 | 10.09 |
| 2020-07-01 | 6_1개월 미만 | 2657 | 597 | 22.47 |
| 2020-07-02 | 1_2년 이상 | 2602 | 503 | 19.33 |
| 2020-07-02 | 2_1년 이상 | 2602 | 623 | 23.94 |
| - | - | - | - | - |
| 2020-07-31 | 1_2년 이상 | 2543 | 517 | 20.33 |
| 2020-07-31 | 2_1년 이상 | 2543 | 570 | 22.41 |
| 2020-07-31 | 3_6개월 이상 | 2543 | 383 | 15.06 |
| 2020-07-31 | 4_3개월 이상 | 2543 | 286 | 11.25 |
| 2020-07-31 | 5_1개월 이상 | 2543 | 296 | 11.64 |
| 2020-07-31 | 6_1개월 미만 | 2543 | 491 | 19.31 |
- 해석
- 7월 1일 기준으로 2년 이상과, 1년 이상 된 유저가 거의 42% + 6개월 이상까지 합하면 5~60%
- 진성 유저들의 점착도가 높은 서비스인 것 같음
WITH tbl_visit_by_joined AS (
SELECT DATE_FORMAT(A.visited_at - INTERVAL 9 HOUR, "%Y-%m-%d") AS d_date,
A.customer_id,
B.created_at AS d_joined,
MAX(A.visited_at) AS last_visit,
datediff(MAX(A.visited_at), B.created_at) AS date_diff
FROM tbl_visit A
LEFT JOIN tbl_customer B
ON A.customer_id = B.customer_id
WHERE A.visited_at >= '2020-07-01'
AND A.visited_at < '2020-08-01'
GROUP BY d_date, A.customer_id, d_joined
)
SELECT A.d_date,
CASE WHEN A.date_diff >= 365*2 THEN '1_2년 이상'
WHEN A.date_diff >= 365 THEN '2_1년 이상'
WHEN A.date_diff >= CEILING(365/2) THEN '3_6개월 이상'
WHEN A.date_diff >= CEILING(365/4) THEN '4_3개월 이상'
WHEN A.date_diff >= 30 THEN '5_1개월 이상'
ELSE '6_1개월 미만' END AS segment,
B.all_users,
COUNT(A.customer_id) AS users,
ROUND(COUNT(A.customer_id)/B.all_users*100,2) AS 'percent(%)'
FROM tbl_visit_by_joined A
LEFT JOIN (SELECT d_date,
COUNT(customer_id) AS all_users
FROM tbl_visit_by_joined
GROUP BY 1) B # B 테이블은 일자별로 해당일자의 전체 고객 숫자
ON A.d_date = B.d_date
GROUP BY 1,2,3
ORDER BY 1,2;
-- 해석 : 7월 1일 기준으로 2년 이상과, 1년 이상 된 유저가 거의 42% + 6개월 이상까지 합하면 5~60%
-- 진성 유저들의 점착도가 높은 서비스인 것 같음
# 쿼리 맞는지 아닌지 체크
SELECT 537+596+389+270+268+597,2657;'패스트캠퍼스 학습일지' 카테고리의 다른 글
| [Final project] 파이널 프로젝트 종료 및 회고 (0) | 2024.03.04 |
|---|---|
| [패스트캠퍼스 DA 부트캠프 11기] 11주차 학습 (1) | 2024.01.05 |
| [2nd project] SQL 프로젝트 종료 및 회고 (0) | 2023.12.26 |
| [패스트캠퍼스 DA 부트캠프 11기]7주차 학습 (0) | 2023.12.07 |
| [패스트캠퍼스 DA 부트캠프 11기]6주차 학습 (1) | 2023.11.30 |